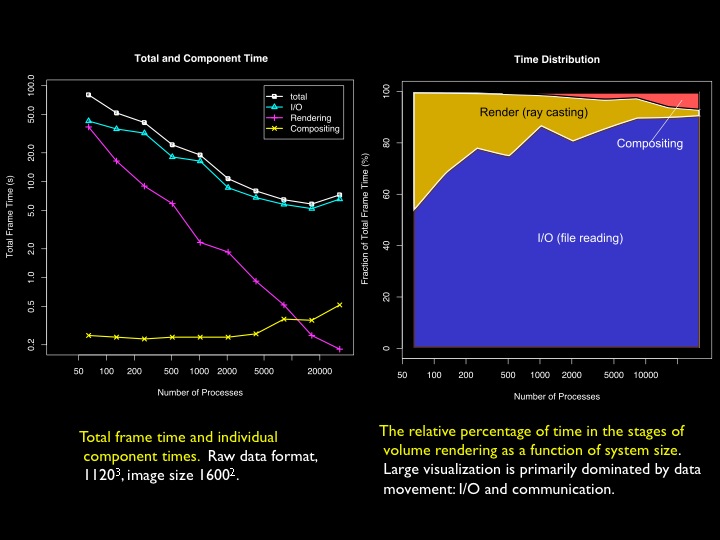
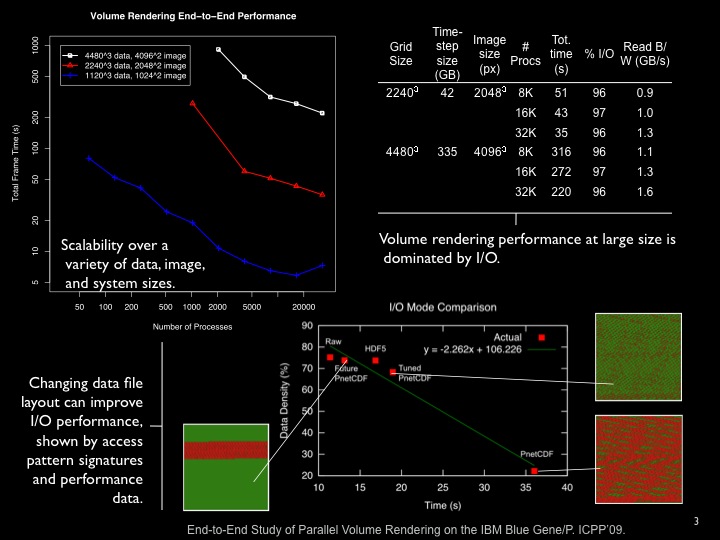
The end-to-end performance of parallel volume rendering is shown below, in total and in terms of I/O, rendering, and compositing components. Total time is dominated by I/O. Further reading: Peterka, T., Yu, H., Ross, R., Ma, K.-L.: Parallel Volume Rendering on the IBM Blue Gene/P. Proceedings of Eurographics Symposium on Parallel Graphics and Visualization 2008 (EGPGV'08) Crete, Greece, April 2008. pdf bibtex
Strong scaling for three volume and image sizes shows good scalability to 32 K processes. The I/O efficiency can be improved with different file layouts. Further reading: Peterka, T., Yu, H., Ross, R., Ma, K.-L., and Latham, R: End-to-End Study of Parallel Volume Rendering on the IBM Blue Gene/P. Proceedings of ICPP'09 Conference, Vienna, Austria, September 2009. pdf bibtex
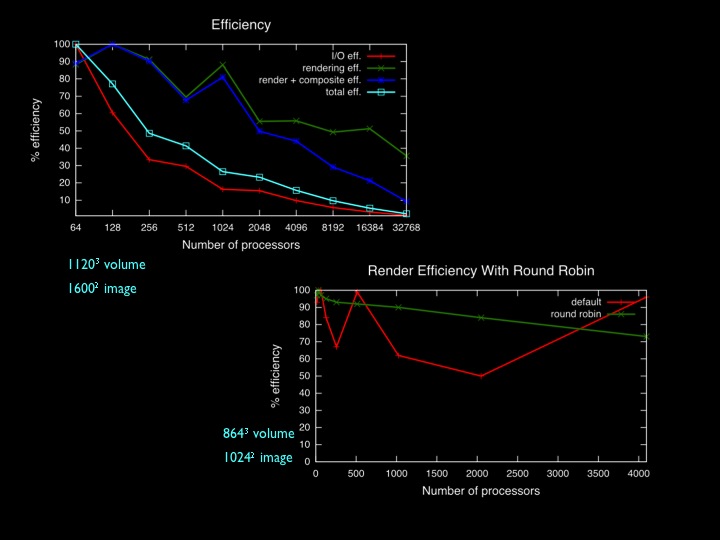
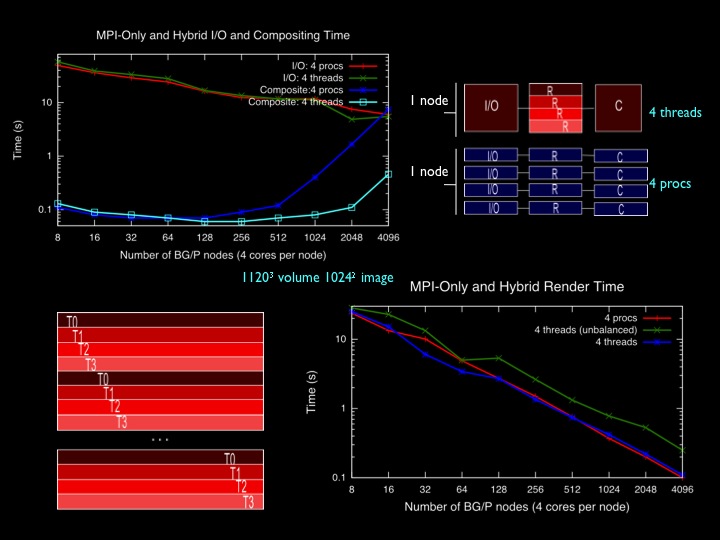
Round robin static block distribution is an inexpensive load balancing scheme that can significantly improve efficiency, and performance of direct-send compositing can be improved with multithreaded - MPI hybrid programming for parallel volume rendering. Further reading: Peterka, T., Ross, R., Yu, H., Ma, K.-L.: Assessing Improvements to the Parallel Volume Rendering Pipeline at Large Scale. Proceedings of SC08 Ultrascale Visualization Workshop, Austin TX, November 2008. pdf bibtex
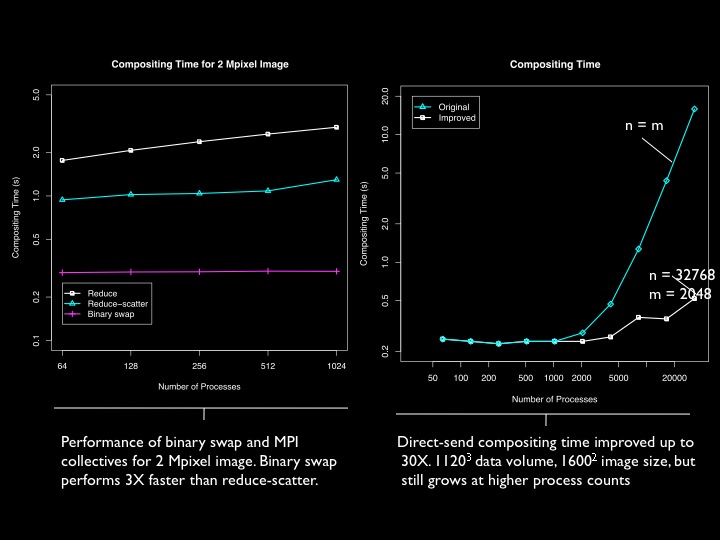
In parallel image compositing, binary swap and direct-send are the accepted approaches. Binary swap outperforms standard reduce and reduce-scatter collective algorithms provided by MPI. Direct-send can be improved by using fewer compositing nodes, but its performance still degrades at tens of thousands of processes. Further reading: Peterka, T., Goodell, D., Ross, R., Shen, H.-W., Thakur, R.: A Configurable Algorithm for Parallel Image-Compositing Applications. Proceedings of SC09, Portland OR, November 2009. pdf bibtex
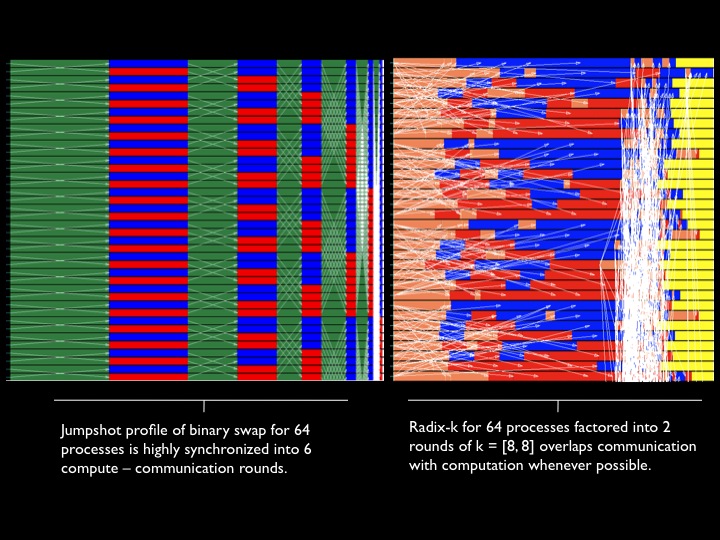
Profiling the performance of binary swap and Radix-k image compositing with MPE and Jumpshot reveals very different communication patterns.
The lower bounds on theoretical complexity for the Radix-k image compositing algorithm are as good or better than other algorithms.

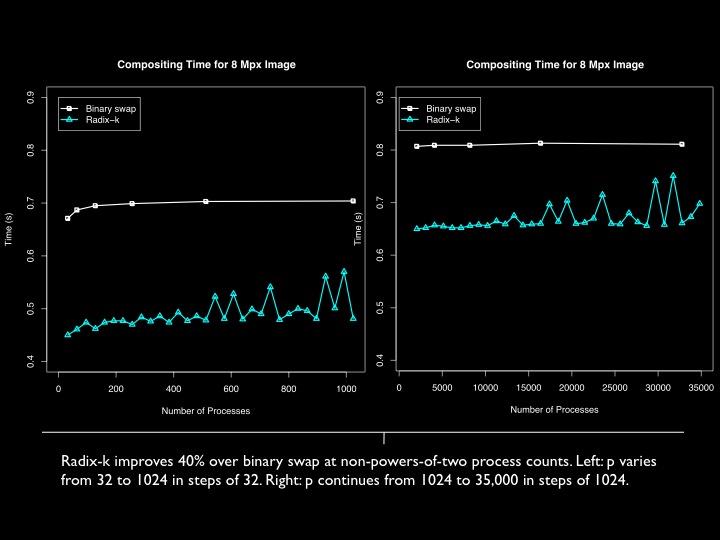
Performance of Radix-k image compositing compared to binary swap on Blue Gene/P Intrepid. The left graph is the first rack in increments of 32 processes; the right graph is successive racks in increments of 1024 processes. No bounding box or run-length encoding optimizations as yet are applied.
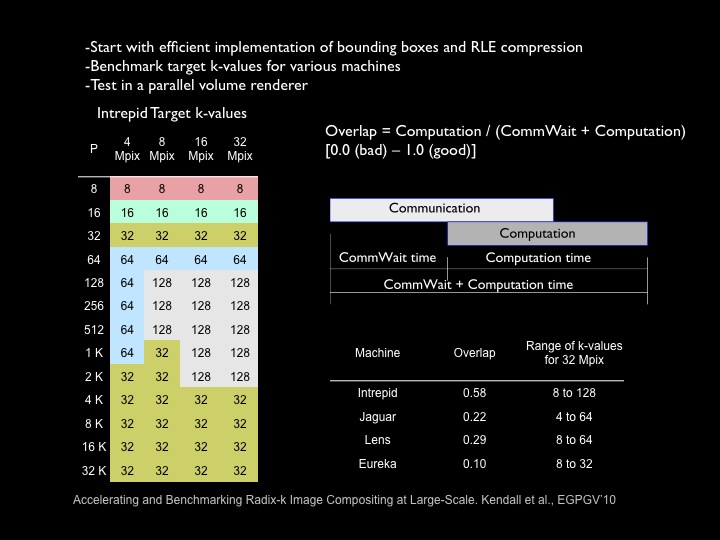
The effect of bounding box and run-length encoding optimizations on Radix-k image compositing is tested for several different machines, and new target k-values are determined. Large scale results are shown. Further reading: Kendall, W., Peterka, T., Huang, J., Shen, H.-W., Ross, R.: Accelerating and Benchmarking Radix-k Image Compositing at Large Scale. Proceedings of EG PGV'10, Norrkoping, Sweden, May 2010. pdf bibtex
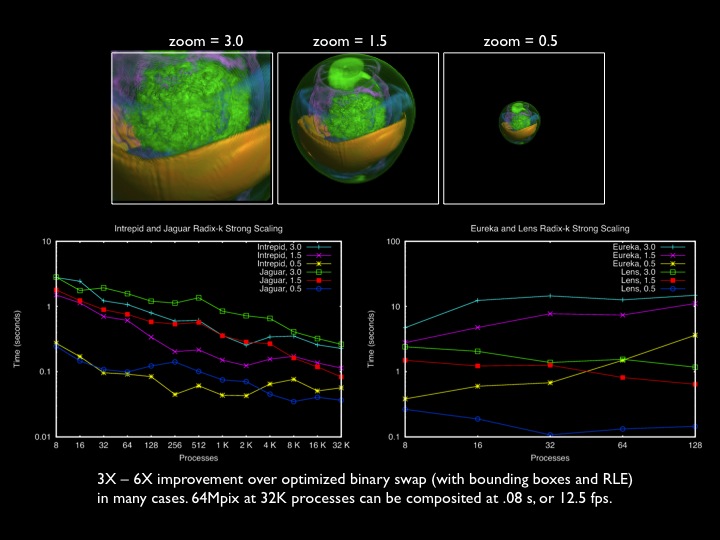
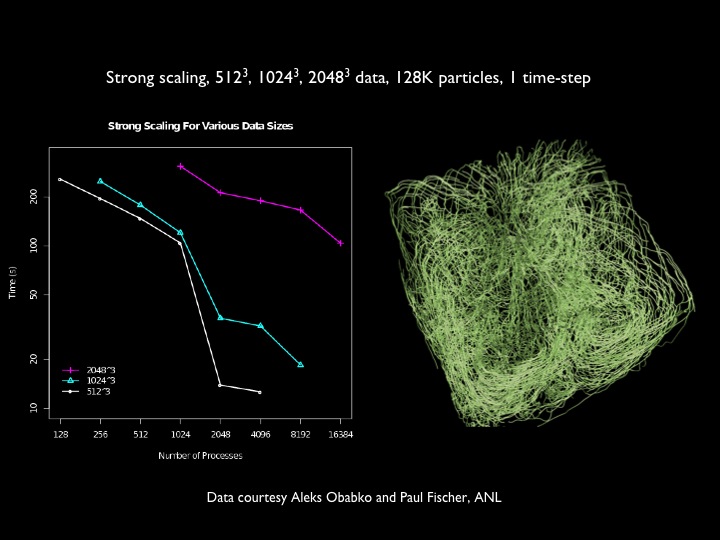
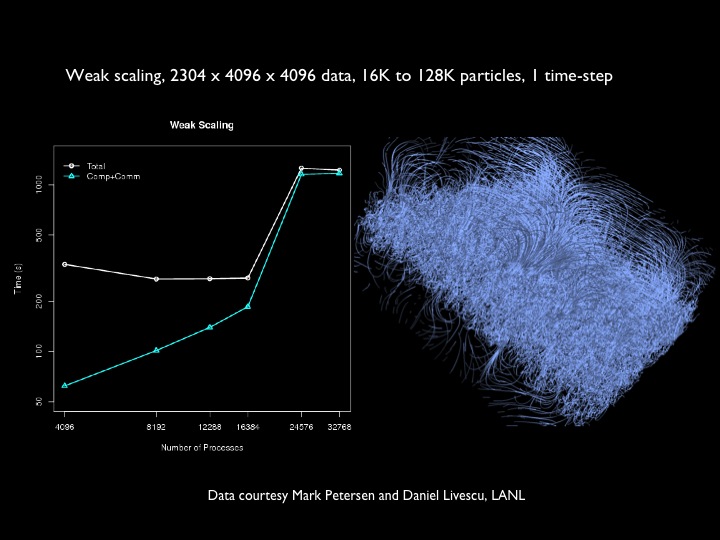
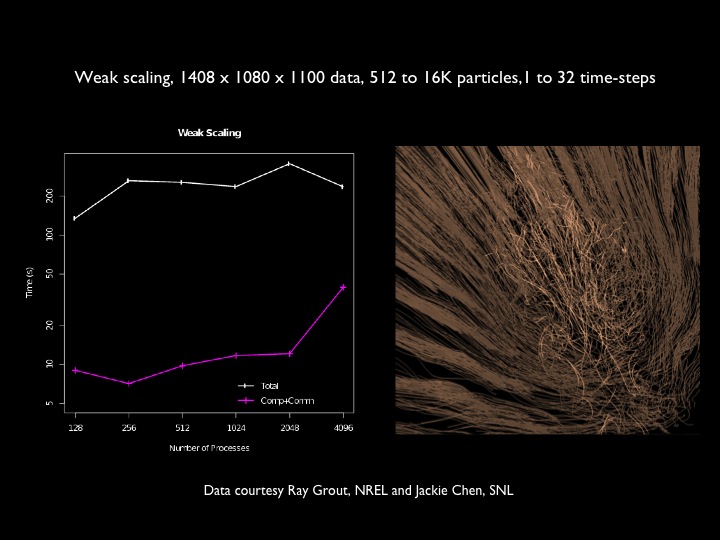
Strong and weak scaling for particle tracing of static and time-varying flow fields is shown below. Datasets are from the MAX experiment, Rayleigh-Taylor instability, and flame stabilization, respectively. Further reading: Peterka, T., Ross, R., Nouanesengsey, B., Lee, T.-Y., Shen, H.-W., Kendall, W., Huang, J.: A Study of Parallel Particle Tracing for Steady-State and Time-Varying Flow Fields. Proceedings IPDPS'11, Anchorage AK, May 2011.