

The application we used is a parallel production code developed at the University of Chicago to to study the gravitational collapse of self-gravitating gaseous clouds. Details about the application and its I/O characteristics can be found in [26].
The application uses several three-dimensional arrays that are distributed in a (block,block,block) fashion. The algorithm is iterative and, every few iterations, several arrays are written to files for three purposes: data analysis, checkpointing, and visualization. The storage order of data in files is required to be the same as it would be if the program were run on a single processor. The application uses two-phase I/O for reading and writing distributed arrays, with I/O routines optimized separately for PFS and PIOFS [26]. I/O is performed by all processors in parallel.
We ran three cases of the application on the SP and Paragon. The three cases on the SP were as follows:
On both machines, we ran the application on 16 processors using a mesh
of size 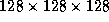 grid points. The application started by
reading a restart
file and ran for ten iterations, dumping arrays every five
iterations. A total of 50Mbytes of data was read at the start, and
around 100Mbytes of data was written every five iterations.
The sizes of individual read/write operations were as follows: there was one
small read of 24bytes and several large reads of 512Kbytes; there
were a few small writes of 24bytes and several large writes of
128Kbytes and 512Kbytes.
grid points. The application started by
reading a restart
file and ran for ten iterations, dumping arrays every five
iterations. A total of 50Mbytes of data was read at the start, and
around 100Mbytes of data was written every five iterations.
The sizes of individual read/write operations were as follows: there was one
small read of 24bytes and several large reads of 512Kbytes; there
were a few small writes of 24bytes and several large writes of
128Kbytes and 512Kbytes.
Tables 3 and 4 show the I/O time taken by the application on the SP and Paragon, respectively. The overhead due to ADIO was very small on both systems. In addition, ADIO allowed us to run the SP version of the application on the Paragon and the Paragon version on the SP, both with very low overhead.
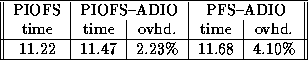
Table 3: I/O time for the production application on 16 processors on
the SP. The three cases are: PIOFS version run
directly, PIOFS version run through ADIO on PIOFS, and
the Intel PFS version run through ADIO on PIOFS. Time in seconds.
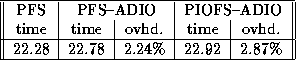
Table 4: I/O time for the production application on 16 processors on
the Paragon. The three cases are: PFS version run
directly, PFS version run through ADIO on PFS, and the
IBM PIOFS version run through ADIO on PFS. Time
in seconds.
Rajeev Thakur