

In the first program, called Program I, each process accesses its own independent file. Each process writes 1Mbyte of data to its local file and reads it back, and this writing and reading procedure is performed ten times. We wrote three different versions of this program: for PFS, PIOFS, and MPI-IO.
The second program, called Program II, is similar to Program I except that all processes access a common file. The data from different processes is stored in the file in order of process rank. Each process writes 1Mbyte of data to a common file and reads it back, and this writing and reading procedure is performed ten times. We also wrote three different versions of this program: for PFS, PIOFS, and MPI-IO.
To determine the overhead due to ADIO, we ran three cases of each program on the SP and Paragon. The three cases run on the SP were as follows:
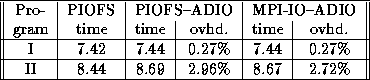
Table 1: I/O time for the test programs on 16 processors on the
SP. The three cases are: PIOFS version run directly, PIOFS
version run through ADIO on PIOFS, and
MPI-IO version run through ADIO on PIOFS. Time
in seconds.
The three cases run on the Paragon were as follows:
Table 2 shows the I/O time for all three cases of the two test programs, run on 16 processors on the Paragon. The overhead of using ADIO was negligible on the Paragon as well. For both test programs, the overhead of using MPI-IO through ADIO was slightly lower than that of PFS through ADIO, possibly because the MPI-IO versions had fewer I/O function calls than the PFS versions. The MPI-IO versions did not use any explicit seek functions. Instead, they used MPIO_Read and MPIO_Write functions that use an offset to indicate the location in the file for reading or writing. The PFS versions, however, used seek calls in addition to the read and write calls.
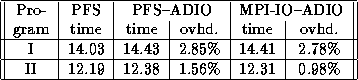
Table 2: I/O time for the test programs on 16 processors on the
Paragon. The three cases are: PFS version run directly, PFS
version run through ADIO on PFS, and MPI-IO version
run through ADIO on PFS. Time in seconds.
Rajeev Thakur