Block Parallelism
This work is in collaboration with Dmitriy Morozov of Lawrence Berkeley National Laboratory.
Block parallelism is our
parallel programming model for scalable data analysis. In this model, data are
decomposed into blocks; blocks are assigned to processing elements (processes or
threads); computation is described as iterations over these blocks, and
communication between blocks is defined by reusable patterns. This programming
model is implemented in our DIY software.
Watch a short video overview here
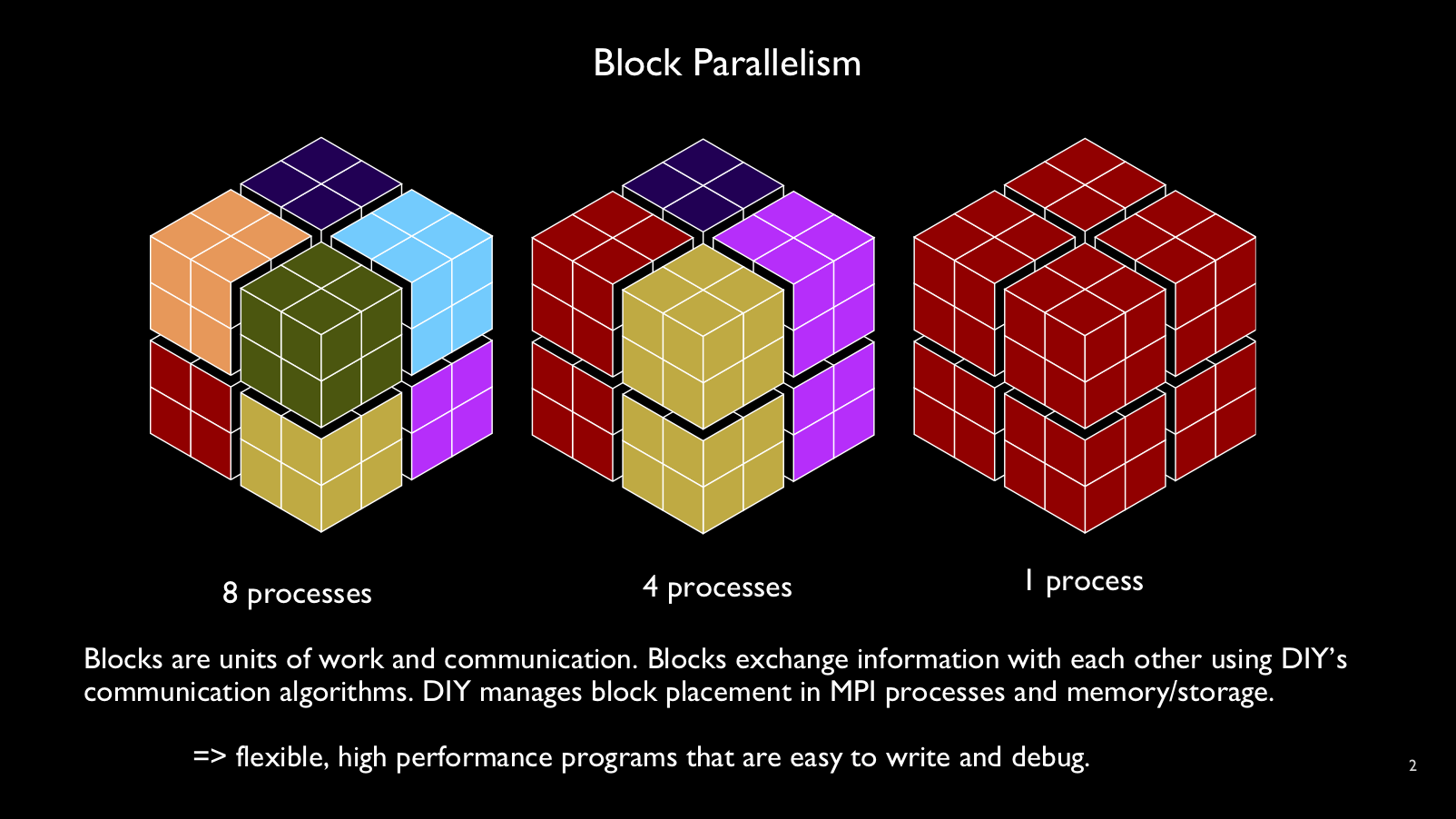
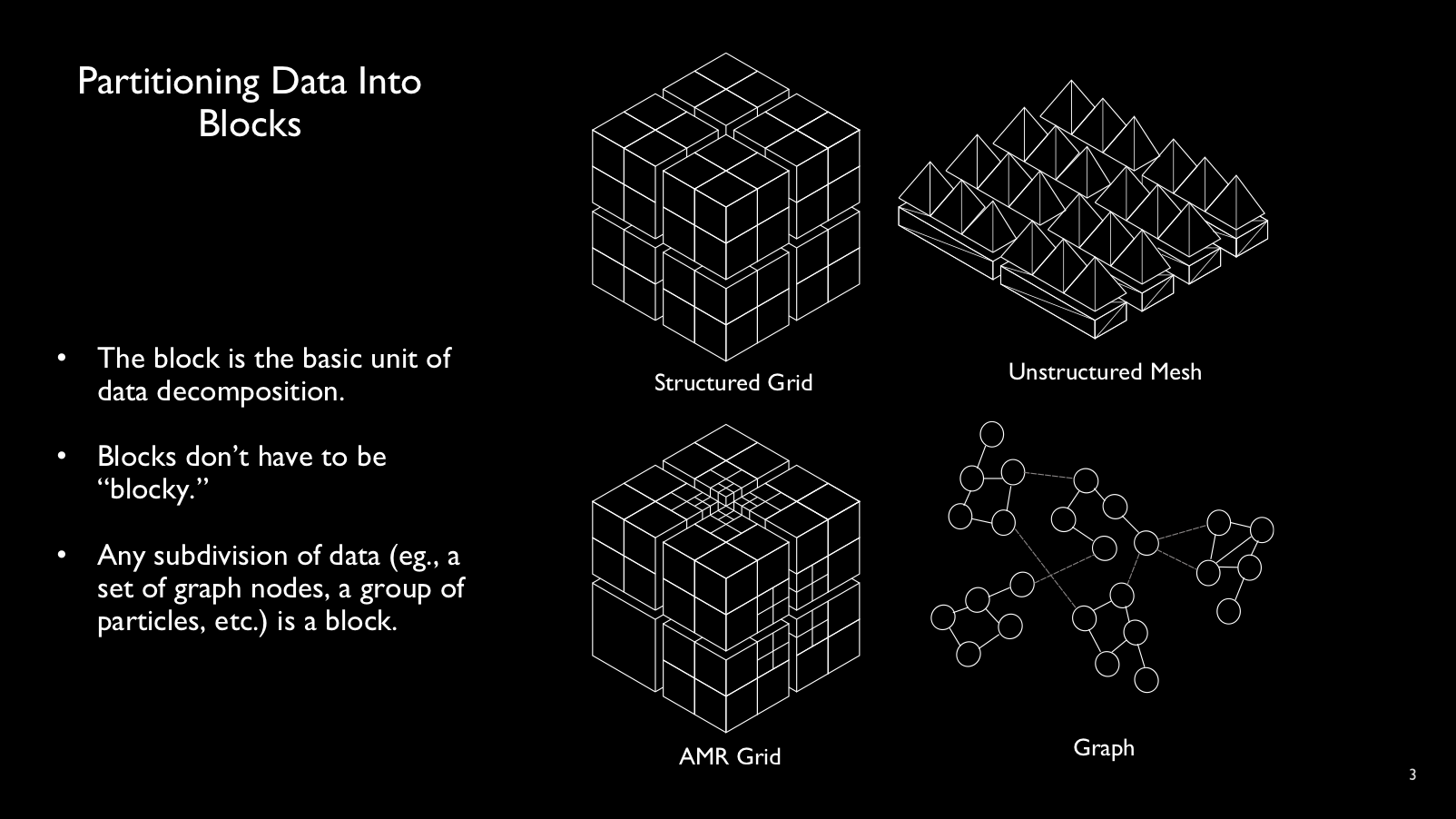
Blocks are subdomains of data and units of parallel work. Despite their name,
blocks can take any form and hold a variety of structured or unstructured
user-defined content. By separating the logical block abstraction from
processors (e.g., MPI ranks), the DIY runtime is free to schedule
blocks to computing resources in flexible ways without changes to the program.
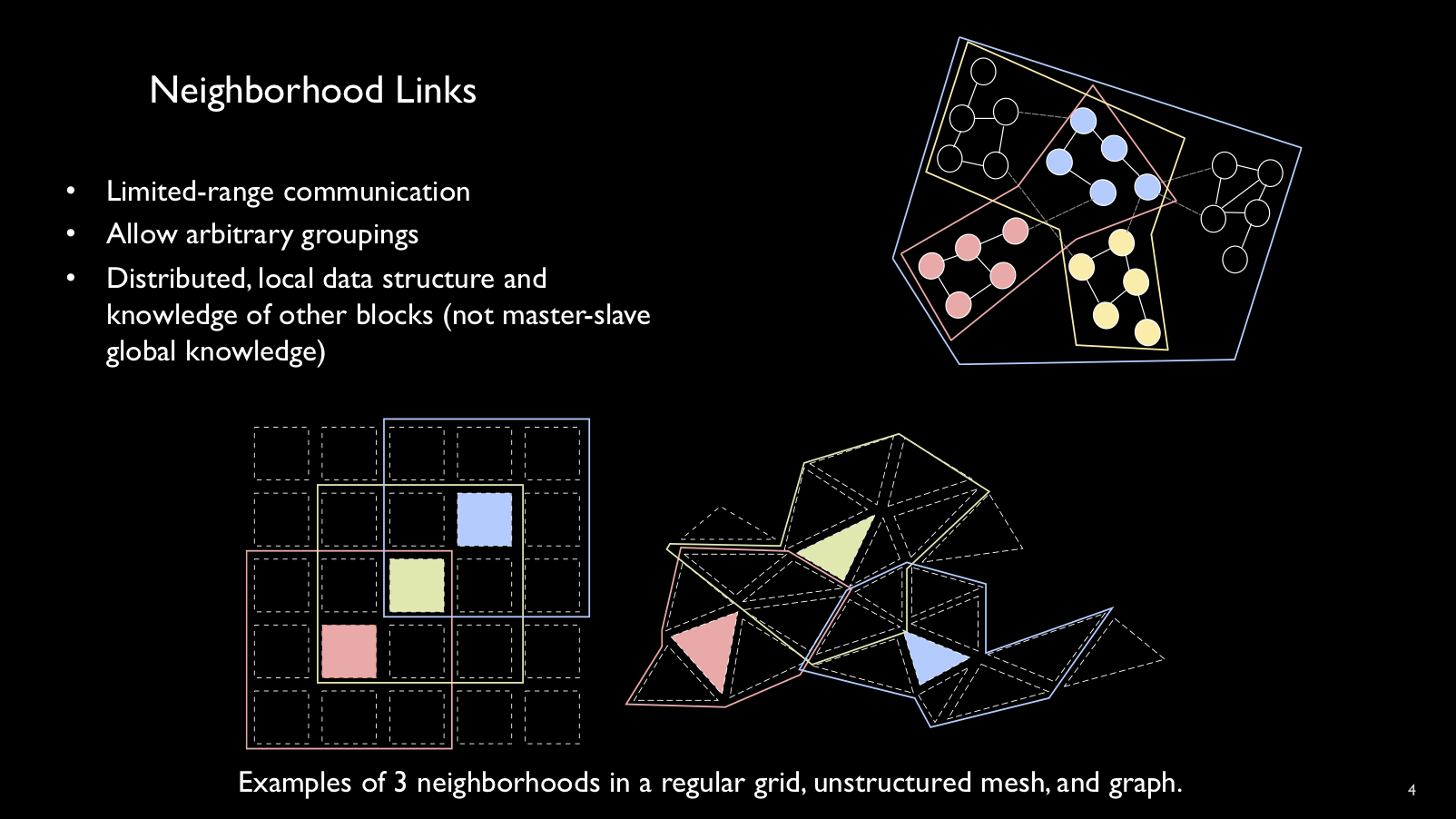
Blocks are organized into local communcation subgraphs called neighborhood
links. The link stores the neighbor block IDs and their MPI ranks.
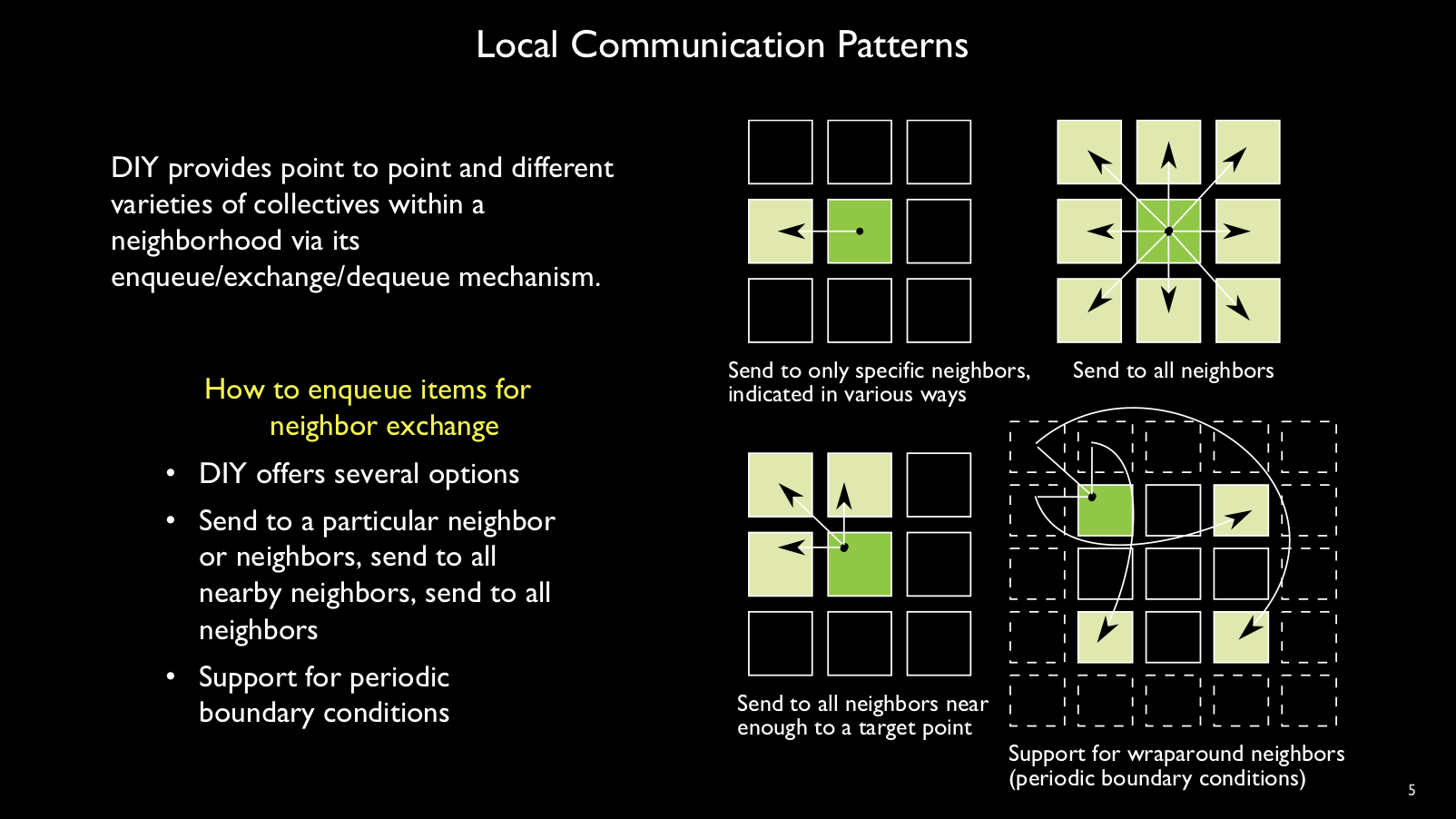
Within a neighborhood link, various communication patterns are possible.
Individual neighbors, local
broadcast to all neighbors, selective neighbors, and periodic boundary
neighbors are some of the options.
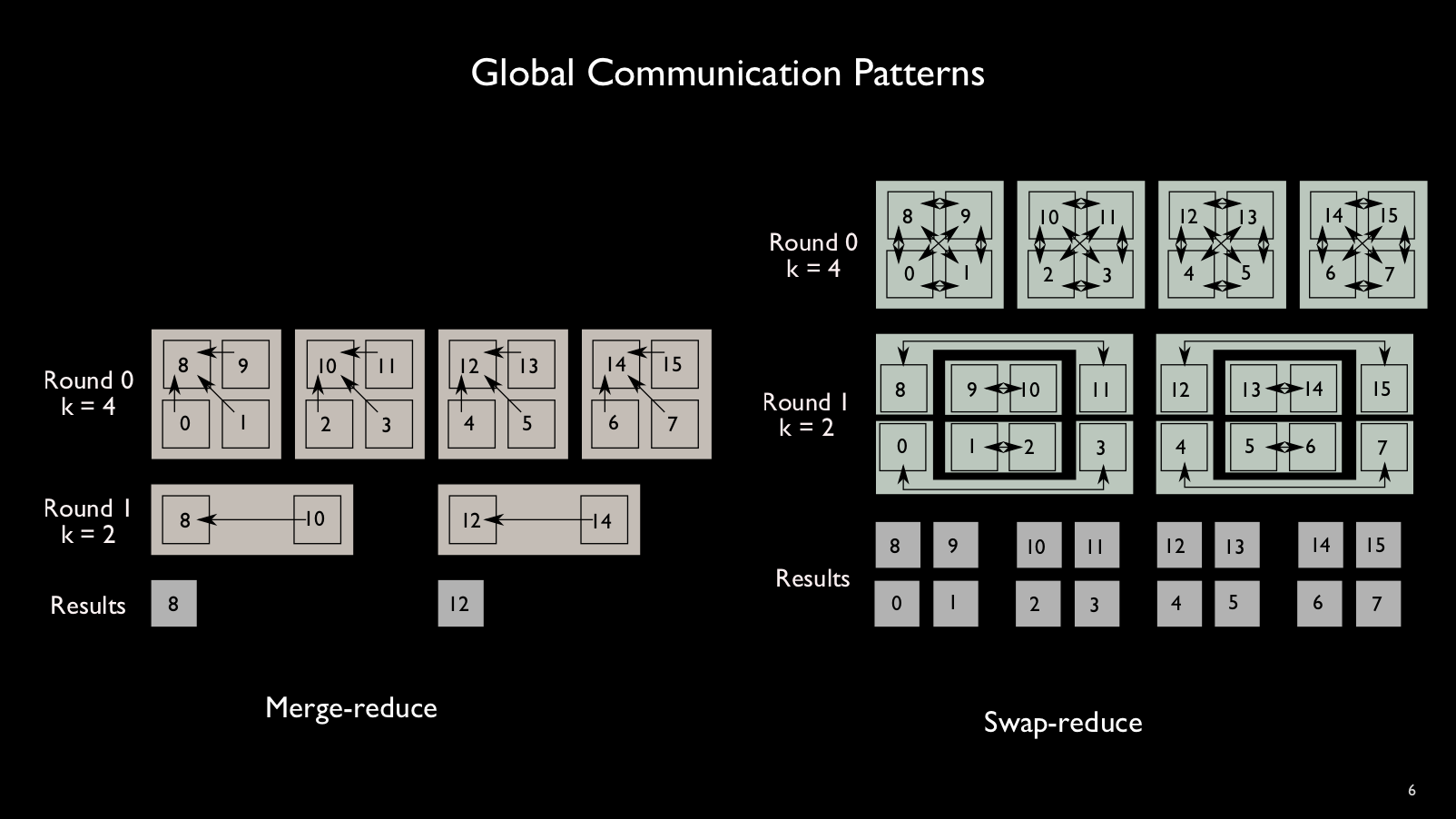
Global reductions between all blocks include merge-reduce, swap-reduce, and
broadcast and are available with a single line of DIY code. The merge-reduce and swap-reduce patterns are shown below.
The listing below shows the typical structure of a DIY program. The master is
the main DIY object that controls all the blocks in an MPI rank. Blocks are
assigned to ranks by DIY's assigner, and regular grids are decomposed by the
decomposer. Computation and communication (local and global) phases are clearly
demarcated. Callback functions written by the user provide
custom operations on blocks.

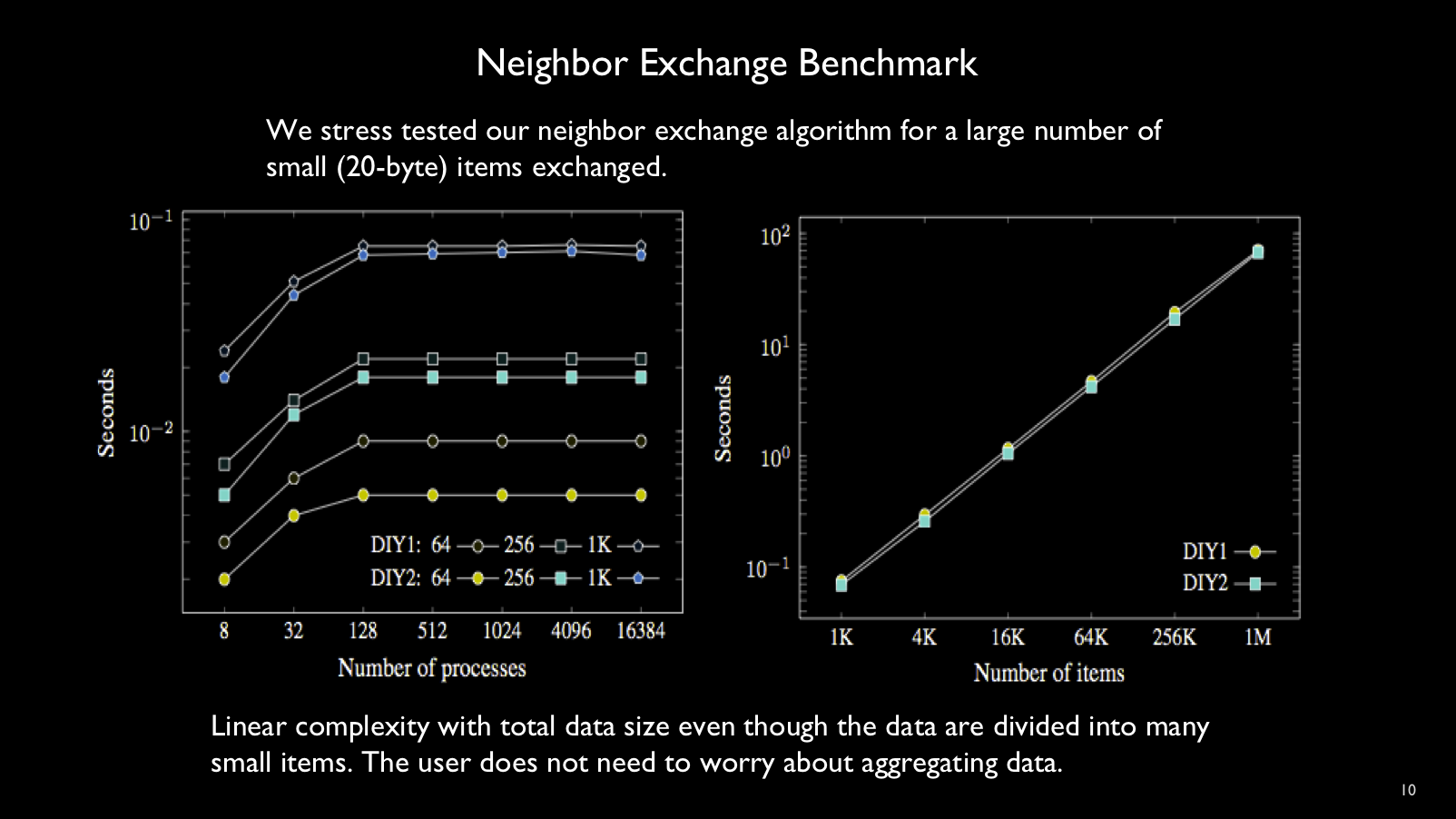
The figure below shows a stress test of DIY neighbor exchange with large
numbers of small items exchanged and measures the enqueue and dequeue rate of
small 20-byte messages.
The total message time is approximately
linear in the total message size, meaning that DIY has no noticeable overheads
as the number of small messages grows very large.
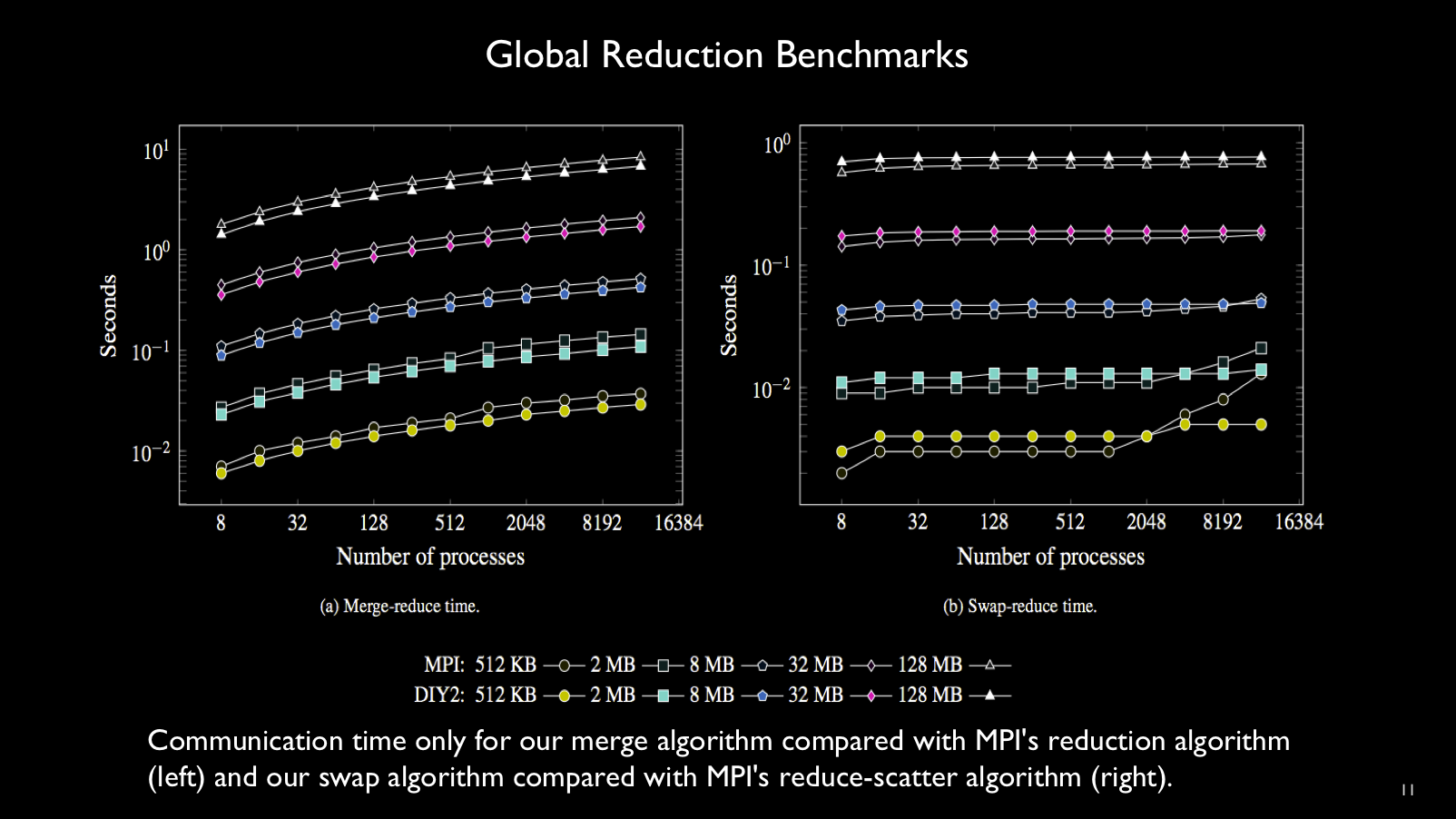
The figure below compares DIY reductions against their MPI counterparts; experiments
were run on the Mira BG/Q machine.
Merge- and swap-reduction performance is compared with MPI Reduce and MPI Reduce
scatter, respectively. Performance comparable with MPI is achieved, even though
DIY's programming model is more flexible and easier to use.
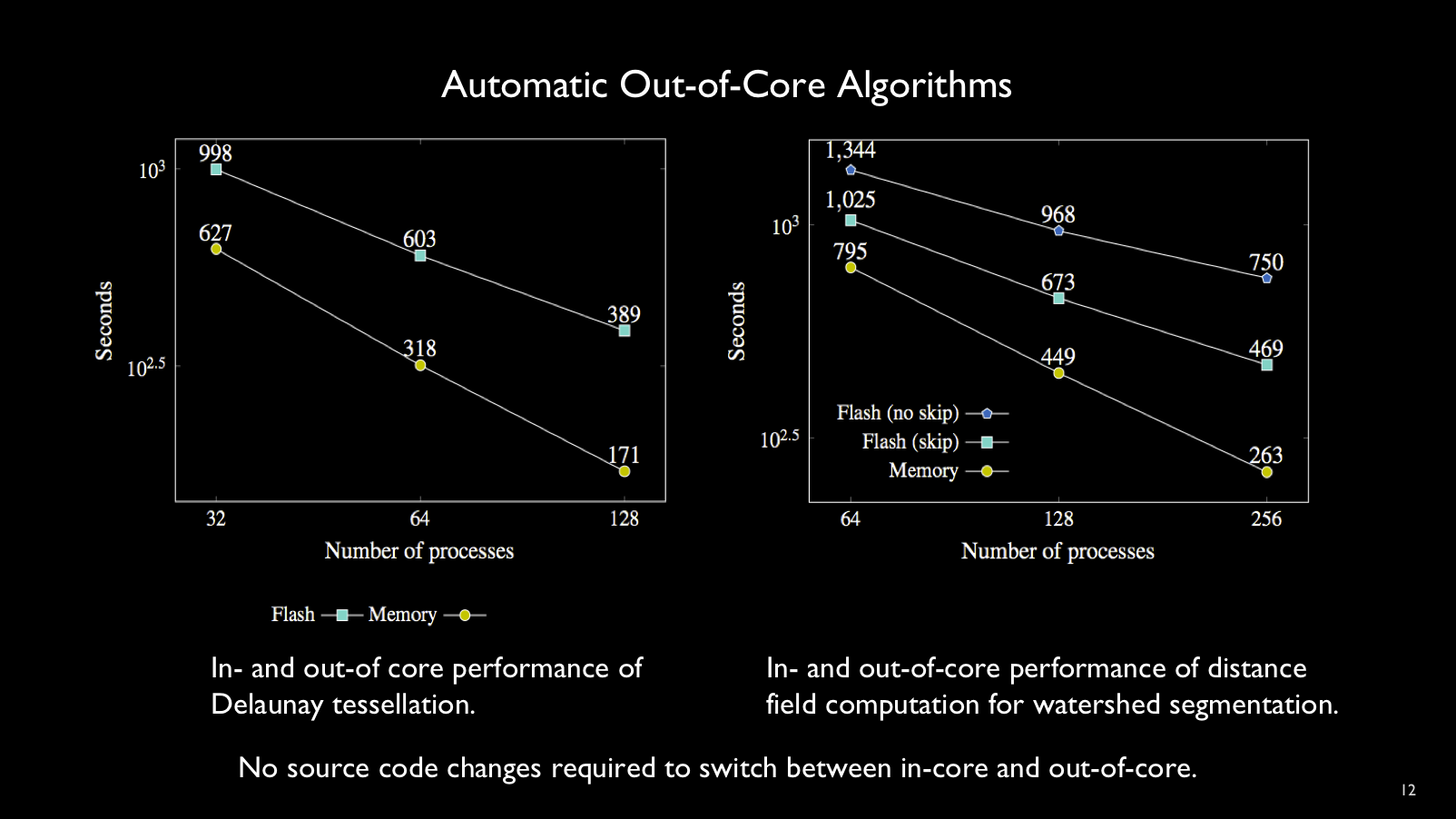
One of DIY's characteristics is the ability to run the same program in
and out-of-core, with no change to the code or recompilation. Performance is of
course slower in the out-of-core regime, but scalability (slope of the curve) is
similar.
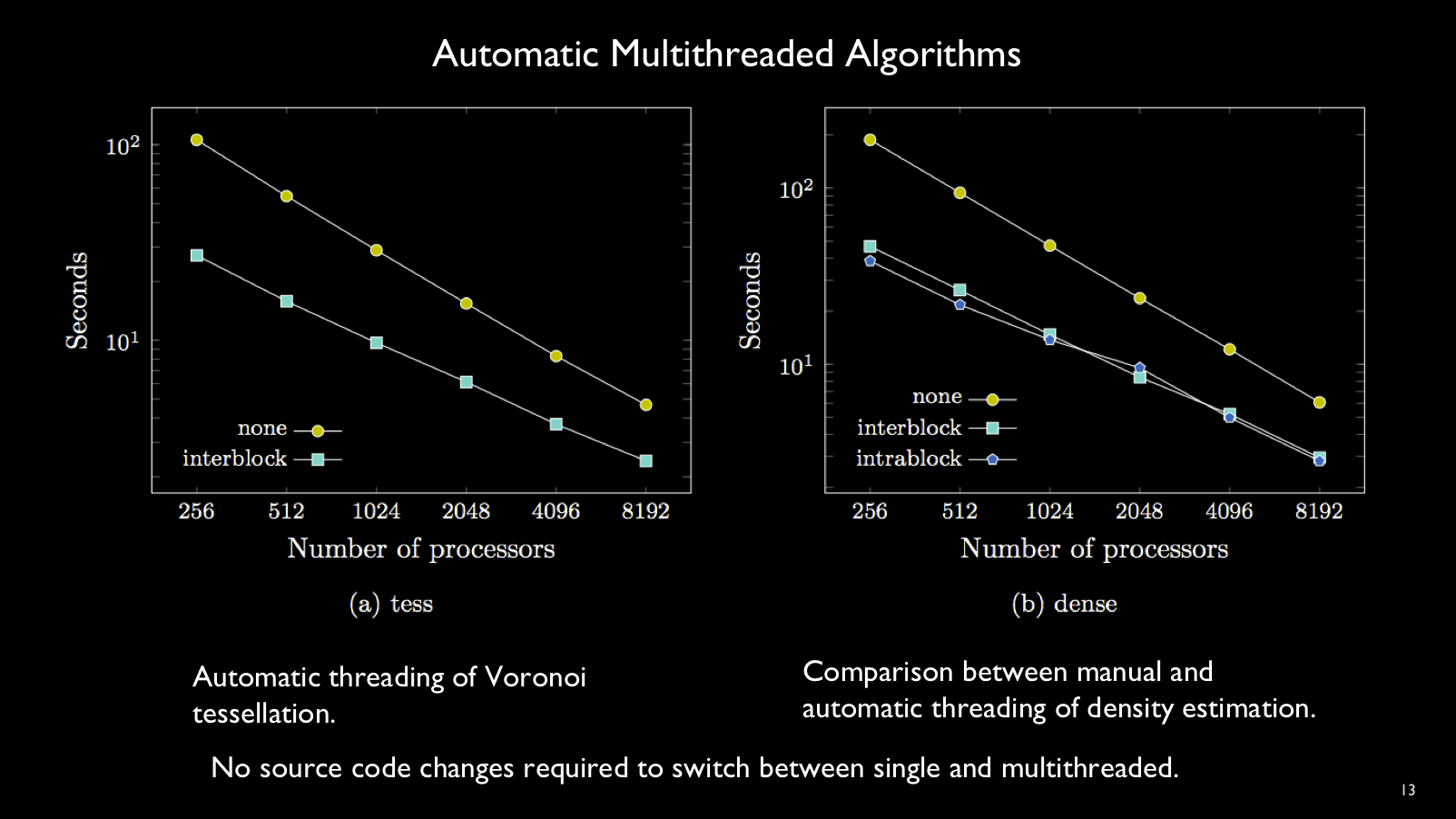
Another convenient feature of the block-parallel abstraction is the ability to
automatically execute multiple blocks in the same MPI rank concurrently.
Performance is comparable to hand-threaded code. Again, no change or
recompilation of the program is needed to enable automatic block threading.
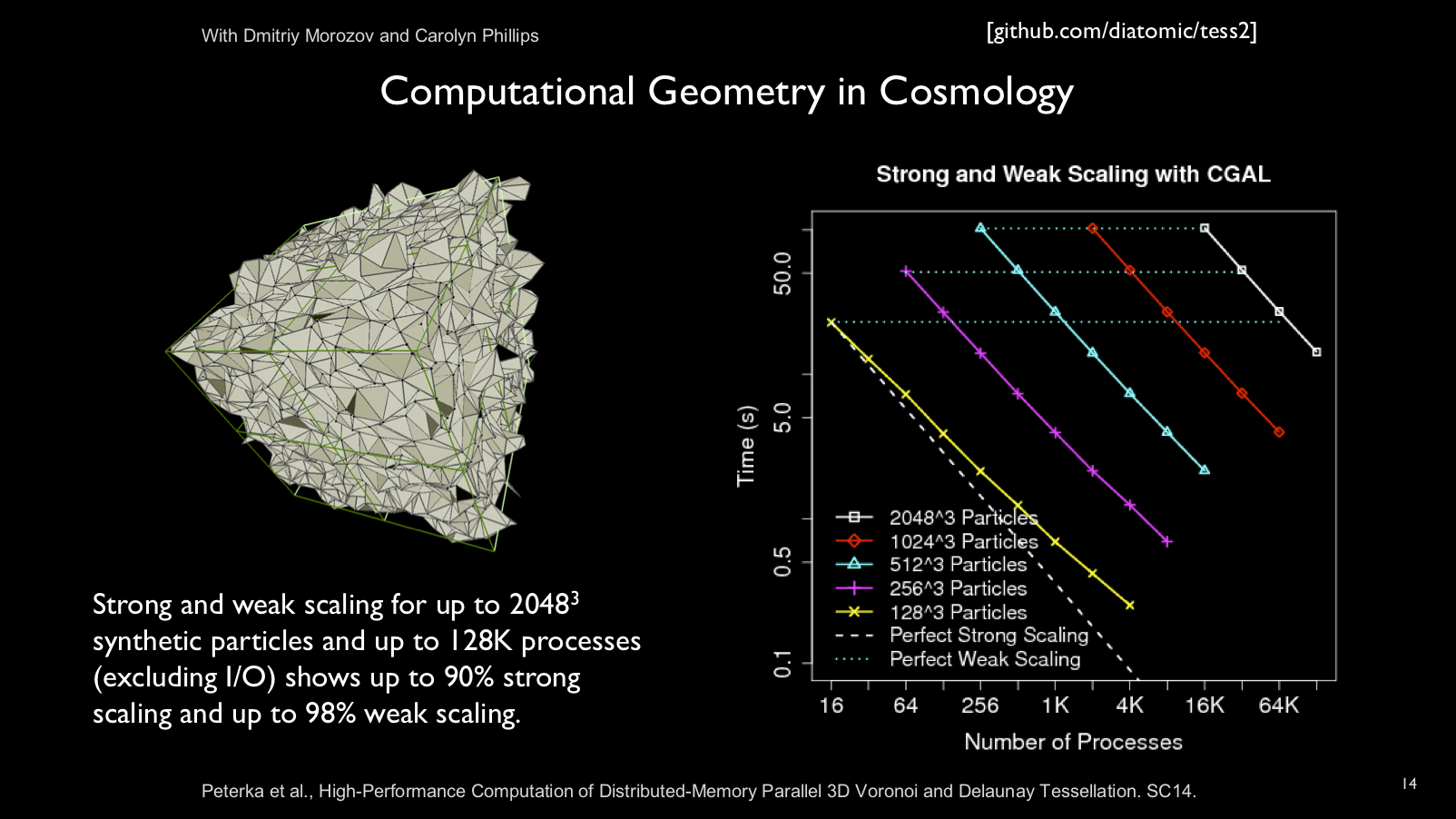
Parallel libraries are built on top of DIY's block-parallel model.
Tess, for example, is a parallel Voronoi and Delaunay
tessellation library.
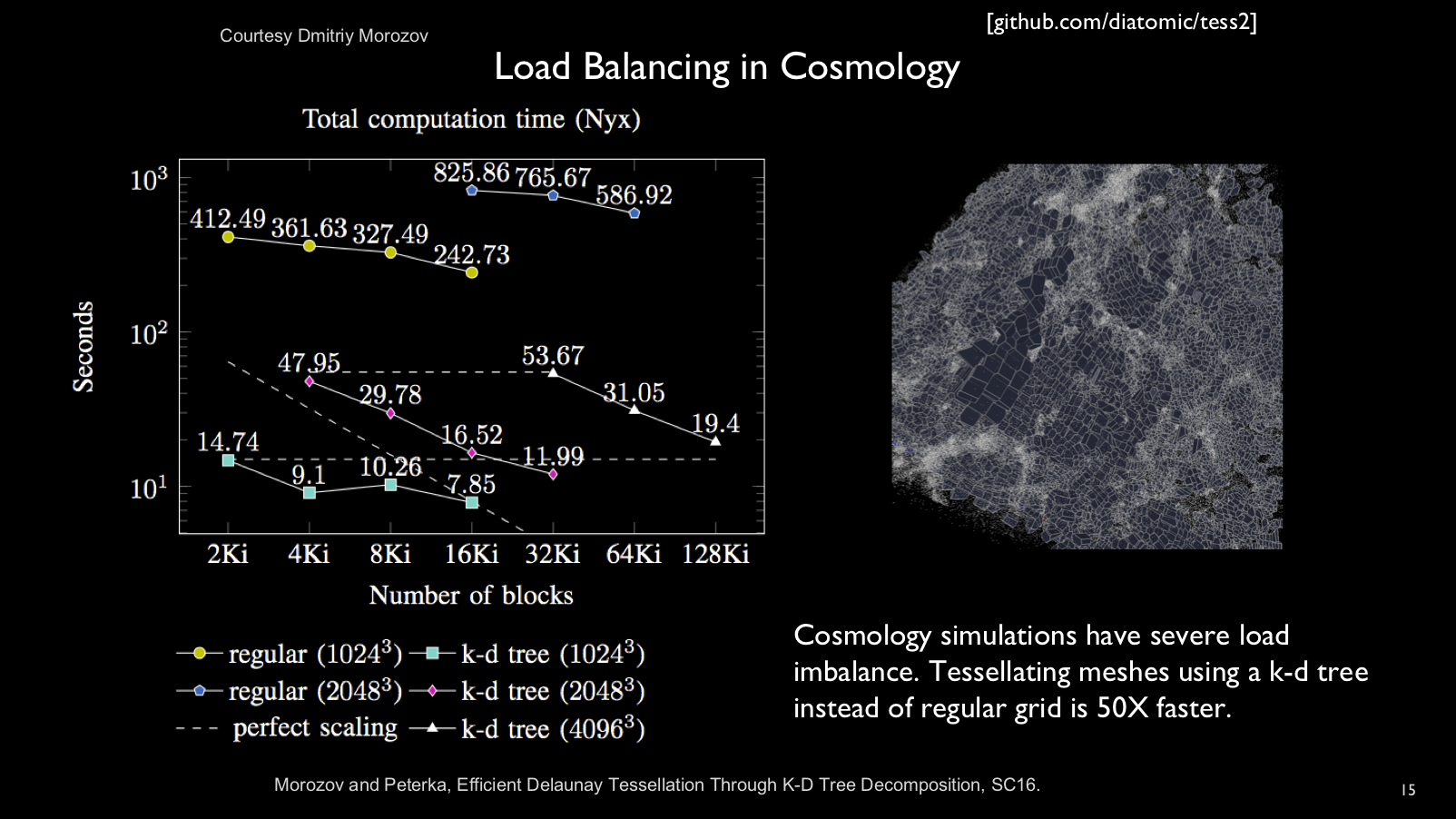
Some applications produce datasets with widely varying data density, resulting
in severe load imabalance when parallelized with a regular block decomposition.
For this reason, we added k-d tree block decomposition to DIY.
Block parallelism is a parallel programming model that shares some similarity
with task-parallel models while retaining some of the familiarity of
traditional parallel programming.
