Algorithm for solving tridiagonal matrix problems in parallel
|
Nathan Mattor, Timothy J. Williams, and Dennis W. Hewett |
|
Lawrence Livermore National Laboratory |
|
Livermore, California 94550 |
[Published as Parallel Computing 21 1769 (1995)]
Abstract
A new algorithm is presented, designed to solve tridiagonal matrix
problems efficiently with parallel computers (multiple instruction stream,
multiple data stream (MIMD) machines with distributed memory).
The algorithm is designed to be extendable to higher order banded diagonal systems.
I. Introduction
Currently, there are several popular methods for parallelization of the
tridiagonal problem.
The ``most important'' of these have
recently been described with a unified approach, through parallel
factorization (Amodio and Brugnano).
Essentially, parallel factorization divides and solves the problem by the
following steps:
-
1.
-
Factor the original matrix into a product of a block matrix (that
can be divided up between processors) and a reduced matrix, which
couples the block problems.
-
2.
-
Solve each block problem with one processor.
-
3.
-
Solve the reduced matrix problem.
Here, we propose a new approach to parallel solution of such systems.
It is conceptually different from parallel factorization, in that
the first step is avoided: no manipulations are performed on the original
matrix before subdividing it among the processors.
Avoiding this step has three advantages: simplicity, speed, and one less stability
concern.
The method here is analogous to the solution of an inhomogeneous linear differential
equation, where the solution is a ``particular'' solution added to an arbitrary linear
combination of ``homogeneous'' solutions.
The coefficients of the homogeneous solutions are later determined by boundary
conditions.
In our parallel method, each processor is given a contiguous subsection of a tridiagonal
system.
Even with no information about the neighboring subsystems, the solution can be obtained
up to two constants.
This completes the bulk of the necesary calculations.
Once each processor has obtained such a solution, the global solution
can be found by matching endpoints.
This approach allows a number of desirable features in both generality and
efficient implementation.
First, the method is readily generalizable to 5-diagonal and higher banded systems,
as discussed in Sec VI.
Second, the particular and homogeneous solutions can be calculated quite
efficiently, since there are a number of overlapping calculations.
Usual serial LU decomposition of a single M×M tridiagonal system requires 8M floating point operations and a temporary storage array of M elements [Press et al. or
Hockney and Eastwood].
For the parallel routine below, the three solutions (one particular and two homogeneous)
are calculated with 13M operations (not 3×8M = 24M) and no additional temporary
storage arrays, while leaving the input data intact.
Third, the interprocessor communication can be performed quite efficiently,
by the all-to-all broadcast method described in Sec. IV.
Finally, vector processors can be utilized effectively in cases where there are
a number of banded diagonal systems to be solved.
This paper gives an implementation of this method.
The algorithm is designed with the following objectives, listed in order of priority.
First, the algorithm must minimize the number of interprocessor communications opened,
since this is the most time consuming process.
Second, the algorithm allows flexibility of the specific solution method of the
tridiagonal submatrices.
Here, we employ a variant of LU decomposition, but this is easily replaced with cyclic
reduction or other.
Third, we wish to minimize storage needs.
The remainder of this paper is organized as follows.
Sec. II outlines the analysis underlying the routine.
Sec. III describes an algorithm for computing the particular and two
homogeneous routines in 13M operations.
Sec. IV gives a method to assemble the reduced system efficiently in each
processor, solve it, and complete the solution.
Sec. V covers time consumption and performance of the algorithm.
Sec. VI gives some conclusions and generalizations of this routine.
The Appendix gives program segments.
II. Basic Algorithm
We consider the problem of solving the N×N linear system
with
|
Λ = |
|‾
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
_|
|
, (2-2) |
|
on a parallel computer with P processors.
For simplicity, we assume N = PM, with M an integer.
Our algorithm is as follows.
First, the linear system of order N is subdivided into P subsystems of
order M.
Thus, the N×N matrix Λ is divided into P
submatrices Lp, each of dimension M×M,
|
Λ = |
|‾
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
_|
|
, (2-5) |
|
where ep is the p-th column of the M×M identity matrix.
Similarly, the N dimensional vectors X and R are divided into
P sub-vectors x and r, each of dimension M
Here the submatrix Lp is given by
|
|
|
|
|‾
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
_|
|
|
| |
|
|
|‾
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
_|
|
, |
| |
|
for p = 1,2,…P, with similar and obvious definitions for x and
r.
For brevity, we have defined amp ≡ AM(p-1)+m, corresponding to
the mth subdiagonal element of the pth submatrix.
Similarly, bmp ≡ BM(p-1)+m and cmp ≡ CM(p-1) +m.
For each subsystem p we define three vectors xpR,
xpUH, and xpLH as the solutions to the equations
The superscripts on the x stand for ``particular'' solution, ``upper homogeneous''
solution, and ``lower homogeneous'' solution respectively, from the inhomogeneous
differential equation analogy.
The general solution of subsystem p consists of xpR added to an arbitrary
linear combination of xpUH and xpLH,
|
xp = xpR + xpUHxpUH + xpLHxpLH, (2-12) |
|
where xpUH and xpLH are yet undetermined coefficients that depend
on coupling to the neighboring solutions.
To find xpUH and xLH, Eq. (2-12) is substituted into Eq. (2-1).
Straightforward calculation and various definitions in this section
show that x1UH = xPLH = 0, and the
remaining 2P-2 coefficients are determined by the solution to the
following tridiagonal linear system, or "reduced" system
|
|
|‾
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
_|
|
|
|‾
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
_|
|
= - |
|‾
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|_
|
| |
‾|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
_|
|
, (2-13) |
|
where xp,m refers to the mth element of the appropriate solution from
the pth submatrix.
The solution of Eq. (2-1), via subdivision and reassembly, is now complete.
The outline of the algorithm is as follows:
-
1.
-
For each processor, find xpR, xpUH, and
xpLH by solving Eqs. (2-9)-(2-11).
-
2.
-
Assemble the ``reduced'' system, Eq. (2-13), and
solve for the xpUH and xpLH.
-
3.
-
For each processor, compute the final solution by Eq. (2-12).
This algorithm is our main result.
The remainder of this paper discusses practical details of reducing operation
count, memory requirement, and communication time.
III. Computing the particular and homogeneous solutions
The three solutions xpR, xpUH, and xpLH are
obtained by solving Eqs. (2-9)-(2-11).
The method here is based on LU decomposition, which is usually the most efficient.
With vector processors, cyclic reduction may be more efficient (Hockney and
Jesshope), but only if just one system need be solved.
Many applications require solution of multiple tridiagonal systems, for which the
most efficient use of vectorization is to use LU decomposition and vectorize across the
multiple systems.
This is discussed further in Sec. VI.
Equations (2-9)-(2-11) represent three M×M tridiagonal systems.
If these systems were independent, then solution via LU decomposition would
require 3×8M = 24M binary floating point operations.
However, exploiting overlapping calculations and elements with value 0, gives the
following algorithm, which can be implemented with 13M binary floating point operations.
|
| | Forward elimination: | |
|
ωi = |
ci
bi-aiωi-1
|
i = 2,3,…M |
| |
|
γi = |
ri-aiγi-1
bi-aiωi-1
|
i = 2,3,…M |
| | Back substitution: | |
|
xRi = γi - ωi xRi+1 i = M-1,M-2,…1 |
| |
|
xLHi = -ωi xLHi+1 i = M-1,M-2,…1 |
| |
|
ωUHi = |
ai
bi-ciωi+1UH
|
i = M-1,M-2,…1 |
| | Forward substitution: | |
| xUHi = -ωUHixUHi-1 i = 2,3,…M, |
|
|
where the processor index p is implicitly present on all variables, and we
have assumed that end elements a1 and cM are written in the appropriate
positions in the a and c arrays.
This algorithm is similar to the usual LU decomposition algorithm, (see, e.g.,
Press et al. or Hockney and Eastwod), but with an extra forward substitution.
The sample FORTRAN segment in the Appendix implements this with no temporary
storage arrays.
If the tridiagonal matrix is constant, and only the right hand side changes from
one iteration to the next, then the vectors ωi,
1/(bi-aiωi), xUHi, and xLHi can be precalculated
and stored.
The computation then requires only 5M binary floating point operations.
IV. Construction and solution of the reduced matrix
Once each processor has determined xpR, xpUH,
and xpLH, it is time to construct and solve the reduced system of
Eq. (2-13).
This section describes an algorithm for this.
We assume that the following subroutines are available for interprocessor
communication:
- Send(ToPid,data,n): When this is invoked by processor
FromPid, the array data of length n is
sent to processor ToPid.
It is assumed that Send is nonblocking, in that the
processor does not wait for the data to be received by
ToPid before continuing.
- Receive(FromPid,data,n): To complete data transmission,
Receive is invoked by processor ToPid.
Upon execution, the array sent by processor FromPid is stored in
the array data array of length n,
It is assumed that Receive is blocking, in that the processor
waits for the data to be received before continuing.
Opening interprocessor communications is generally the most
time-consuming step in the entire tridiagonal solution process, so it is important
to minimize this.
The following algorithm consumes a time of T = (log2P)tc in opening
communication channels (where tc is the time to open one channel).
- Each processor writes whatever data it has that is relevant to
Eq. (2-13) in the array OutData.
-
The OutData arrays from each processor are concatenated as
follows (Fig. 1):
-
Each procesor p sends its OutData array to processor
p-1 mod P, and receives a corresponding array from processor
p+1 mod P, as depicted in Fig. 1a.
The incoming array is concatenated to the end
of OutData.
-
At the ith step, repeat the first step, except sending to
processor p-2i-1 mod P, and receiving from processor p+2i-1 mod P
(Fig. 1b,c), for i = 1,2,….
After log2P iterations (or the next higher integer), each
processor has the contents of the reduced matrix in the OutData
array.
-
Each processor rearranges the contents of its OutData array
into the reduced tridiagonal system, and then solves. (Each processor solves the same
reduced system.)
This communication is dense (every processor communicates in every step), and
periodic, so that upon completion every processor contains the fully concatenated
OutData array).
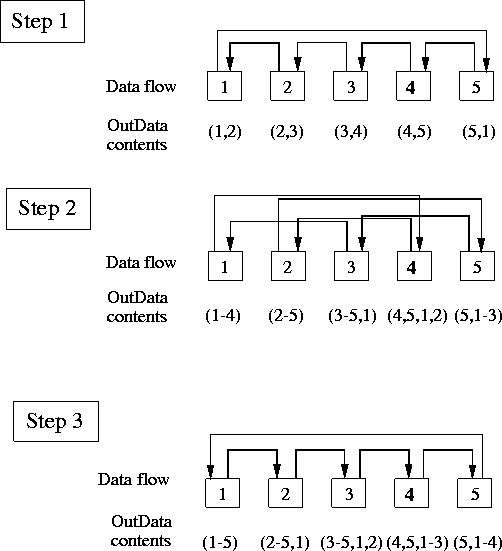
-
Figure 1.
-
Illustration of the method used to pass reduced
matrix data between processors, with P = 5 for definiteness.
- step 1:
-
In the first iteration, each processor p
sends data to processor (p-1) mod P+1, receives data from
processor (p+1) mod P+1, and concatenates the data arrays.
The result is that each OutData array contains the
data from the processors shown, in order shown. The remaining
elements of the OutData array are not used.
- step 2:
-
Each processor sends its OutData
array to processor (p-2) mod P+1, receives data from processor
(p+2) mod P+1, again concatenating.
- step 3:
-
In the ith iteration (here third and
final), each processor sends its OutData array to
processor (p-2i-1) mod P+1, receives data from processor
(p+2i-1) mod P+1, again concatenating. The final
OutData array contains all the information of the
reduced matrix, ordered cyclically beginning with the contributions
of the pth processor. The information beyond the element
Outdata(8P) is not used.
A sample program segment is provided in the Appendix.
If the elements of the tridiagonal matrix are constants, then the reduced
matrix can be precalculated and only the reduced right hand side needs to be
assembled.
In this case, the above routine could be rewritten to pass 1/4 as many real
numbers.
This does not represent a very large time savings, since generally it is the
channel openings that is the most costly, not the amount of data passage.
At this point, the necessary components to Eq. (2-12) are stored in each
processor.
All that is left is the trivial task of picking out the correct coefficients
and constructing the final solution.
A sample program segment is provided in the Appendix.
V. Performance
In this section we discuss execution time of this algorithm,
and present scaling tests made with a working code.
The time consumption for this routine is as follows.
-
1.
-
To calculate the three roots xR, xUH, and
xLH requires 13M binary floating point operations by each
processor, done in parallel.
-
2.
-
To assemble the reduced matrix in each processor requires
log2P steps where interprocessor communications are opened, and
the ith opening passes 8×2i-1 real numbers.
-
3.
-
Solution of the reduced system through LU decomposition requires
8(2P-2) binary floating point operations by each processor.
-
4.
-
Calculation of the final solution requires 4M binary floating point
operations by each processor, done in parallel.
If tb is the time of one binary floating point operation,
tc is the time required to open a communication channel (latency), and
tp is the time to pass one real number once communication is opened,
then the time to execute this parallel routine is given by (optimally)
|
|
|
@ 13Mtb + (log2P)tc + 8(P-1)tp + 8(2P-2)tb + 4Mtb |
| |
|
@ (17M+16P)tb + (log2P)tc + 8Ptp, |
| |
|
for P >> 1.
For cases of present interest, TP is dominated by (log2P)tc and 17M tb.
The parallel efficiency is defined by eP ≡ [(TS)/(P TP)],
where TS is the execution time of a serial code which solves by LU decomposition.
Since serial LU decomposition solve an N×N system in a time TS = 8Ntb, then
the predicted parallel efficiency is
|
eP = |
8
17+16P2/N+(log2P)Ptc/Ntb + 8P2tp/Ntb
|
. (5-2) |
|
To test these claims empirically, the execution times of working serial and parallel codes
were measured, and eP was calculated both through its definition and through
Eq. (5-2).
Fig. 2 shows eP as a function of P for two cases, N = 200 and N = 50,000.
We conclude from Fig. 2 that Eq. (5-2) (smooth lines) is reasonably accurate, both
for the theoretical maximum efficiency (47%, acheived for small P and large N) and
for the scaling with large P.
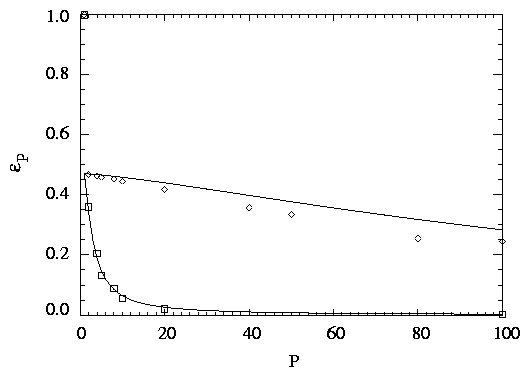
-
Figure 2.
-
Results of scaling runs, comparing the parallel
time with serial LU decomposition time. Here, eP is the
parallel efficiency and P is the number of processors. The
smooth lines represent Eq. (5-2), and the points are empirical
results. The upper line and diamonds use N = 200, and the lower line
and squares use N = 50,000.
These timings were made on the BBN TC2000 MIMD machine at Lawrence Livermore National
Laboratory.
This machine has 128 M88100 RISC processors, connected by a butterfly-switch
network.
To calculate the predictions of Eq. (5-1), the times tc, tp, and tb
were obtained as follows.
We chose tc = 750msec, based on the average time of a send/receive pair
measured in our code.
Based on communications measurements for the BBN (Leith), we chose
the passage time of a single 64-bit real number as tp = 9msec.
[In comparison, the peak bandwidth specification for the machine of 38 MB/sec per path
(BBN Advanced Computers Inc.) would yield tp = 0.2msec.
Using this value instead of 9msec makes no visible differences in Figure 2.]
We chose tb = 1.4msec, based on our measured timing of 0.00218 sec for the
serial algorithm on the N = 200 case.
(In comparison, the peak performance specification of 10 MFLOPS for the M88100
on 64-bit numbers would yield tb = 0.1msec.
Using this value instead of 1.4msec would yield curves which fall well below
our measured parallel efficiency values.)
All measurements were made with 64-bit floating point arithmetic.
It is difficult to make a comprehensive comparison with all other parallel tridiagonal
solvers, but we can compare our speed with a popular algorithm by H. Wang.
That routine requires 2P-2 steps where communications are opened (compared with
log2P such steps here), and 21M binary operations per processor (compared with 17M
here).
We have not performed empirical comparisons, but since both dominant processes
have lower counts, it seems reasonable to believe the present algorithm is generally
faster.
VI. Discussion and Conclusions
In this paper, we have described a numerical routine for solving tridiagonal
matrices using a multiple instruction stream/multiple data stream (MIMD) parallel
computer with distributed memory.
The routine has the advantage over existing methods in that the initial factorization
step is not used, leading to a simpler, and probably faster, routine.
Stability of this algorithm is similar to that of serial LU decomposition of a tridiagonal
matrix.
If the Li are unstable to LU decomposition, then pivoting could be used.
If the Li are singular, then LU decomposition fails and some alternative should
be devised.
If the large matrix Λ is diagonally dominant,
(|Ai| > |Bi|+|Ci|) then so too are the Li.
If the reduced system is unstable to LU decomposition, this can be replaced by a
different solution scheme, with little loss of overall speed (if P << M).
This routine is generalizable from tridiagonal to higher systems.
For example, in a 5-diagonal system, there would be four homogeneous solutions,
each with an undetermined coefficient.
The coefficients of the homogeneous solutions would be determined by a reduced
system analogous to Eq. (2-13), except with O(4P) equations, not 2P-2.
We briefly discuss implementation of this routine in a problem where there are
many tridiagonal systems to solve.
This situation arises in many of the forseeable applications of parallel tridiagonal
solvers, such as solving differential equations by the alternating-direction
implicit method (ADI) (Press et al.) on a multidimensional grid.
For definiteness we consider the two dimensional grid depicted in Fig. 3.
For each grid line in y, there is a tridiagonal system to solve, with the
index running in the x direction.
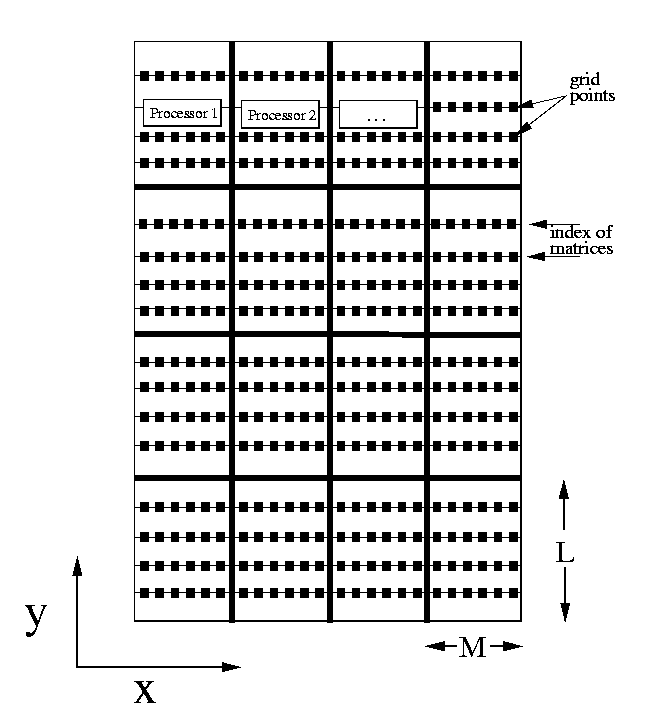
-
Figure 3.
-
Schematic representation of
a typical set of tridiagonal systems that might arise in a two
dimensional grid. For each grid line in y, there is a
tridiagonal system to solve.
The routine described in this paper is well suited for this problem, which
may be handled efficiently as follows.
-
1.
-
The grid is divided into block subdomains in x and y.
Each processor is assigned one subdomain, with the submatrices and
sub-right hand sides stored locally.
If the number of y grid lines in each subdomain is L, and the number of x
grid points is M, then each processor has L systems with M equations each.
-
2.
-
Each processor finds xR, xUH, and xLH, for each y grid line in its subdomain, by the algorithm described
in Sec. III.
-
3.
-
To assemble the reduced systems, each family of processors colinear
in x passes the reduced system data for all y grid lines in the
subdomain, by the algorithm described in Sec. IV.
(Note that the number of communication openings can be minimized by passing
all L reduced systems together.)
After this step is complete, each processor contains L reduced systems, one
for each y grid line in its subdomain.
-
4.
-
Each processor solves the L reduced systems, then assembles the
final solution, as described at the end of Sec. IV.
This method has several desirable features.
First, the time spent opening interprocessor communications is Pxlog2Px (where Px is the number of processors colinear in x), which is not
greater than for solving a single system with Px processors.
Insofar as this is the most time consuming step, multidimensional efficiency
is quite good for this algorithm.
Second, if the processors are vector processors, the calculations for the
y grid lines (steps 1 and 3 above) can be carried out in parallel.
This would seem to be a more efficient use of vectorization than replacing
the LU decomposition with cyclic reduction, since the former involves fewer
operations.
Third, the algorithm is easily converted to a system where the roles of x and
y are reversed; all that needs to be done is exchange indices.
Complicated rearrangement of subdomains is not necessary.
This work was performed for the U.S. Department of Energy at Lawrence
Livermore National Laboratory under contract W7405-ENG-48.
Appendix
This Appendix gives sample FORTRAN routines for the algorithms in Secs. III and IV.
This makes the algorithms more concrete, and also gives some time and memory
saving steps not mentioned above.
The particular and homogeneous solutions for each submatrix are computed by the algorithm
in Sec. III.
This is to be run by each processor, and it is assumed that the arrays
a1p…aMp, b1p…bMp, c1p…cMp, and
r1p…rMp are stored locally in each processor, with the index p
omitted.
No temporary arrays are needed; all intermediate storage is done in the final
solution arrays, xr, xuh, and xlh
(each with M elements).
!forward elimination:
xuh(1) = c(1)/b(1)
xlh(1) = r(1)/b(1)
do i = 2,M,1
denom = b(i) - c(i)*xuh(i-1)
if (denom.eq.0) pause !LU decomposition fails
xuh(i) = c(i)/denom
xlh(i) = (r(i) - a(i)*xlh(i-1))/denom
end do
!back substitution:
xr(M) = xlh(M)
xlh(M) = -xuh(M)
xuh(M) = a(M)/b(M)
do i = M-1,1,-1
xr(i) = xlh(i) - xuh(i)*xr(i+1)
xlh(i) = -xuh(i)*xlh(i+1)
denom = b(i) - c(i)*xuh(i+1)
if (denom.eq.0) pause !LU decomposition fails
xuh(i) = -a(i)/denom
end do
!forward substitution:
xuh(1) = -xuh(1)
do i = 2,M,1
xuh(i) = -xuh(i)*xuh(i-1)
end do
Sec. IV describes how the reduced matrix is written to each processor.
A sample routine follows, to be executed by each processor.
We assume the processors are numbered p = 1,2,…,P.
The integer pid is the local processor number (called p in the
mathematical parts of this paper), and the integer nprocs is the
code name for P.
The integer log2P is the smallest integer greater than or equal
to log2(P).
The real array OutData has 8×2log2P
elements.
The subroutine tridiagonal(a,b,c,r,sol,n) (not given here)
is a serial subroutine that returns the solution sol
for the tridiagonal system with subdiagonal a, diagonal
b, superdiagonal c, and right hand side
r, all of length n.
!write contributions of current processor into OutData:
OutData(1) = -1.
OutData(2) = xuh(1)
OutData(3) = xlh(1)
OutData(4) = -xr(1)
OutData(5) = xuh(M)
OutData(6) = xlh(M)
OutData(7) = -1.
OutData(8) = -xr(M)
!concatenate all the OutData arrays:
log2P = log(nprocs)/log(2)
if (2**log2P.lt.nprocs) log2P = log2P+1
do i = 0,log2P-1,1
nxfer = 8*(2**i)
ToProc = 1 + mod(pid-2**i+2*nprocs,nprocs)
FromProc = 1 + mod(pid+2**i,nprocs)
call Send(ToProc,OutData,nxfer)
call Receive(FromProc,OutData(nxfer+1),nxfer)
end do
!Put OutData into reduced tridiagonal form:
nsig=8*nprocs !no. of significant entries in OutData
ifirst=8*(nprocs-pid) + 5 !index of a(1) in OutData
do i = 1,2*nprocs-2,1
ibase = mod(ifirst+4*(i-1),nsig)
reduca(i) = OutData(ibase)
reducb(i) = OutData(ibase+1)
reducc(i) = OutData(ibase+2)
reducr(i) = OutData(ibase+3)
end do
!solve reduced system:
call tridiagonal(reduca,reducb,reducc,reducr,coeffs,2*nprocs-2)
Once the reduced matrix is solved, then the solution can be assembled in each processor
as follows.
!pick out the appropriate elements of coeffs:
if (processor.ne.1) then
uhcoeff = coeffs(2*processor-2)
else
uhcoeff = 0.
end if
if (processor.ne.nprocs) then
lhcoeff = coeffs(2*processor-1)
else
lhcoeff = 0.
end if
!compute the final solution:
do i = 1,M,1
x(i) = xr(i) + uhcoeff*xuh(i) + lhcoeff*xlh(i)
end do
References
P. Amodio and L. Brugnano, Parallel Factorizations and Parallel
Solvers for Tridiagonal Linear Systems, Linear algebra and its
applications 172: 347-364 (1992).
BBN Advanced Computers Inc., Inside the TC2000 Computer, Cambridge, MA, 25
(1989).
R. W. Hockney and J. W. Eastwood, Computer Simulation Using
Particles, copyright 1988, Adam Hilger, Bristol, p. 185.
R. W. Hockney and C. R. Jesshope, Parallel Computers 2 (copyright
1988 by IOP Publishing, Ltd., Bristol).
C. E. Leith,``Domain Decomposition Message Passing for Diffusion and Fluid Flow,''
in The MPCI Yearly Report: The Attack of the Killer Micros, UCRL-ID-107022
(1991).
William H. Press, Brian P. Flannery, Saul A. Teukolsky, and William T. Vetterling, Numerical Recipes, copyright 1986, Cambridge
University Press, pp. 19-40.
H. H. Wang, A parallel method for tridiagonal equations, ACM
Trans. Math. Software 7:170-183 (1981).
File translated from
TEX
by
TTH,
version 2.60.
On 16 Dec 1999, 16:22.