Rajeev Thakur
[email protected]
http://www.mcs.anl.gov/~thakur
William Gropp
[email protected]
http://www.mcs.anl.gov/~gropp
Ewing Lusk
[email protected]
http://www.mcs.anl.gov/~lusk
I/O is a major bottleneck in many parallel applications. Although the I/O subsytems of parallel machines may be designed for high performance, a large number of applications achieve only about a tenth or less of the peak I/O bandwidth. The main reason for poor application-level I/O performance is that parallel-I/O systems are optimized for large accesses (on the order of megabytes), whereas parallel applications typically make many small I/O requests (on the order of kilobytes or even less). The small I/O requests made by parallel programs are a result of the combination of two factors:
With such an interface, the file system cannot easily detect the overall access pattern of one process individually or that of a group of processes collectively. Consequently, the file system is constrained in the optimizations it can perform. Many parallel file systems also provide their own extensions to or variations of the traditional Unix interface, and these variations make programs nonportable.
To overcome the performance and portability limitations of existing parallel-I/O interfaces, the MPI Forum (made up of parallel-computer vendors, researchers, and application scientists) defined a new interface for parallel I/O as part of the MPI-2 standard [7]. We call this interface MPI-IO. MPI-IO is a rich interface with many features designed specifically for performance and portability, such as support for noncontiguous accesses, collective I/O, nonblocking I/O, and a standard data representation. We believe that MPI-IO has the potential to solve many of the problems users currently face with parallel I/O.
One way to port a Unix-I/O program to MPI-IO is to replace all Unix-I/O functions with their MPI-IO equivalents. Such a port is easy but is unlikely to improve performance. To get real performance benefits with MPI-IO, users must use some of MPI-IO's advanced features. In this paper, we focus on a key feature of MPI-IO: the ability to access noncontiguous data with a single I/O function call by defining file views with MPI's derived datatypes. We describe how derived datatypes allow users to express compactly and portably the entire I/O access pattern in their applications. We explain how critical it is that users create and use these derived datatypes and how such use enables an MPI-IO implementation to perform optimizations. In particular, we describe two optimizations our implementation, ROMIO [15], performs: data sieving and collective I/O. We use a distributed-array example and an unstructured code to illustrate the performance improvements these optimizations provide.
The rest of this paper is organized as follows: Section 2 gives an overview of the ROMIO MPI-IO implementation. In Section 3, we briefly explain the concept of derived datatypes in MPI and how they are used in MPI-IO. In Section 4, we provide a classification of the ways in which an application's I/O access pattern can be expressed in MPI-IO. Section 5 describes some of the optimizations possible when users describe entire access patterns by using derived datatypes. Performance results on five different parallel machines are presented in Section 6, followed by conclusions in Section 7.
We have developed a high-performance, portable implementation of
MPI-IO, called ROMIO. ROMIO is freely available in the form of source
code from the Web site http://www.mcs.anl.gov/romio. The first
version of ROMIO was released in October 1997; the latest version,
1.0.1, was released in July 1998.
ROMIO works on most parallel computers and networks of workstations and can use multiple file systems. Specifically, ROMIO 1.0.1 runs on the following machines: IBM SP; Intel Paragon; HP Exemplar; SGI Origin2000; NEC SX-4; other symmetric multiprocessors from HP, SGI, Sun, DEC, and IBM; and networks of workstations (Sun, SGI, HP, IBM, DEC, Linux, and FreeBSD). Supported file systems are IBM PIOFS, Intel PFS, HP HFS, SGI XFS, NEC SFS, NFS, and any Unix file system (UFS). ROMIO 1.0.1 includes all functions defined in the MPI-2 I/O chapter except shared-file-pointer functions, split-collective-I/O functions, support for file interoperability, I/O error handling, and I/O error classes. Both C and Fortran versions of functions are provided. ROMIO has been designed to be used with any MPI-1 implementation -- both portable and vendor-specific implementations. It is currently included as part of two MPI implementations: MPICH and HP MPI.
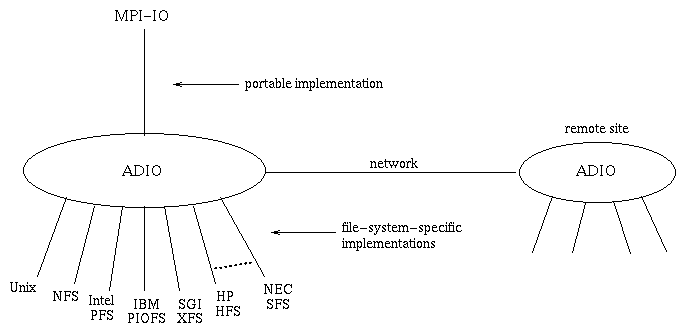
A key component of ROMIO that enables such a portable MPI-IO implementation is an internal layer called ADIO [13]. ADIO, an abstract-device interface for I/O, consists of a small set of basic functions for parallel I/O. MPI-IO is implemented portably on top of ADIO, and only ADIO is optimized separately for different file systems, as shown in Figure 1. Such an approach makes it easier to port ROMIO to new environments. A similar abstract-device interface is used in MPICH for implementing MPI portably [4].
Figure 1: ROMIO Architecture: MPI-IO is implemented portably on top of
an abstract-device interface called ADIO, and ADIO is optimized
separately for different file systems.
In MPI-1, the amount of data a function sends or receives is specified as a number of datatypes [6]. Datatypes in MPI are of two kinds: basic and derived. Basic datatypes are those that correspond to the basic datatypes in the host programming language -- integers, floating-point numbers, and so forth. In addition, MPI provides datatype-constructor functions to create derived datatypes consisting of multiple basic datatypes located either contiguously or noncontiguously. The different kinds of datatype constructors in MPI are as follows:
The datatype created by a datatype constructor can be used as an input datatype to another datatype constructor. Any noncontiguous data layout can therefore be represented in terms of a derived datatype.
MPI-IO uses MPI datatypes for two purposes: to describe the data layout in the user's buffer in memory and to define the data layout in a file. The former is the same as in MPI message-passing functions and can be used, for example, when the user's buffer represents a local array with a ``ghost area'' that is not to be written to the file. The latter, a new feature in MPI-IO, is the mechanism a process uses to describe the portion of a file it wants to access, also called a file view. The file view can be defined by using any MPI basic or derived datatype; therefore, any general, noncontiguous access pattern can be compactly represented.
Several studies have shown that, in many parallel applications, each process needs to access a number of relatively small, noncontiguous portions of a file [1, 2, 8, 10, 14]. From a performance perspective, it is critical that the I/O interface can express such an access pattern, as it enables the implementation to optimize the I/O request. The optimizations typically allow the physical I/O to take place in large, contiguous chunks, even though the user's request may be noncontiguous. MPI-IO's file views are, therefore, critical for performance. Users must ensure that they describe noncontiguous access patterns in terms of a file view and then call a single I/O function; they must not try to access each contiguous portion separately as in Unix I/O.
Any application has a particular ``I/O access pattern'' based on its I/O needs. The same I/O access pattern can, however, be presented to the I/O system in different ways, depending on which I/O functions the application uses and how. We classify the different ways of expressing I/O access patterns in MPI-IO into four ``levels,'' level 0-level 3. We explain this classification with the help of an example, accessing a distributed array from a file, which is a common access pattern in parallel applications.
Consider a two-dimensional array distributed among 16 processes in a (block, block) fashion, as shown in Figure 2. The array is stored in a file corresponding to the global array in row-major order, and each process needs to read its local array from the file. The data distribution among processes and the array storage order in the file are such that the file contains the first row of the local array of process 0, followed by the first row of the local array of process 1, the first row of the local array of process 2, the first row of the local array of process 3, then the second row of the local array of process 0, the second row of the local array of process 1, and so on. In other words, the local array of each process is located noncontiguously in the file.

Figure 2: Distributed-array access
Figure 3 shows four ways in which a user can express this access pattern in MPI-IO. In level 0, each process does Unix-style accesses -- one independent read request for each row in the local array. Level 1 is similar to level 0 except that it uses collective-I/O functions, which indicate to the implementation that all processes that together opened the file will call this function, each with its own access information. Independent-I/O functions, on the other hand, convey no information about what other processes will do. In level 2, each process creates a derived datatype to describe the noncontiguous access pattern, defines a file view, and calls independent-I/O functions. Level 3 is similar to level 2 except that it uses collective-I/O functions.

Figure 3: Pseudo-code that shows four ways of accessing the data in
Figure 2 with MPI-IO
The four levels also represent increasing amounts of data per request, as illustrated in Figure 4.2 It is well known that the larger the size of an I/O request, the higher is the performance. Users, therefore, must strive to express their I/O requests as level 3 rather than level 0. How good the performance is at each level depends on how well the implementation takes advantage of the extra access information at each level.
If an application needs to access only large, contiguous pieces of data, level 0 is equivalent to level 2, and level 1 is equivalent to level 3. Users need not create derived datatypes in such cases. Many real parallel applications, however, do not fall into this category [1, 2, 8, 10, 14].
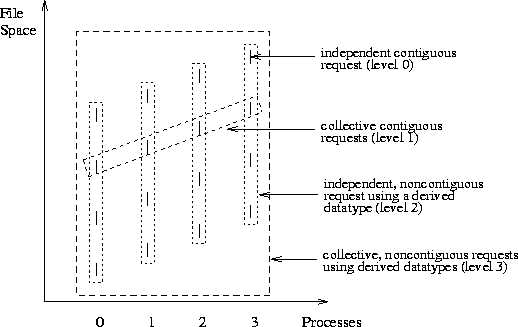
Figure 4: The four levels representing increasing amounts of data per request
We describe some of the optimizations an MPI-IO implementation can perform when the user uses derived datatypes to specify noncontiguous accesses. The first two optimizations, data sieving and collective I/O, are implemented in ROMIO [15]. The third, improved prefetching and caching, is not explicitly implemented in ROMIO, but it is implied by the other two optimizations, as explained below.
To reduce the effect of high I/O latency, it is critical to make as few requests to the file system as possible. Data sieving [12] is a technique that enables an implementation to make a few large, contiguous requests to the file system even if the user's request consists of several small, noncontiguous accesses. The basic idea in data sieving is to make large I/O requests and to extract, in memory, the data that is really needed. When the user makes a read request for noncontiguous data, ROMIO reads large, contiguous chunks, starting from the first requested byte in the file, into a temporary buffer in memory and then copies the requested portions into the user's buffer. More data is read than is actually needed, but the benefit of reading large, contiguous chunks far outweighs the cost of reading unwanted data (see Section 6). The intermediate buffering requires extra memory, but ROMIO uses a constant buffer size that does not increase with the size of the user's request. By default, the maximum buffer size for reading with data sieving is set to 4 Mbytes. The user can, however, change this size at run time via MPI-IO's hints mechanism.
Noncontiguous write requests are handled similarly, except that ROMIO must perform a read-modify-write to avoid destroying the data in the gaps between the portions the user actually wants to write. In the case of independent write requests, during the read-modify-write, ROMIO must also lock the corresponding portion of the file, because other processes may independently try to access portions that are interleaved with this access. In this case, if the size of the data ROMIO accesses at a time is too large, contention among processes for locks can decrease parallelism. For this reason, ROMIO uses a smaller default buffer size, 512 Kbytes, for writing with data sieving than for reading. The user can also change this size at run time.
The collective-I/O functions in MPI-IO must be called by all processes that together opened the file.3 This property enables the implementation to analyze and merge the requests of different processes. In many cases, the merged request may be large and contiguous, although the individual requests were noncontiguous. The merged request can therefore be serviced efficiently [3, 5, 9, 11].
ROMIO has an optimized implementation of collective I/O that uses a generalized version of the extended two-phase method described in [11]. The basic idea is to perform I/O in two phases: an I/O phase and a communication phase. In the I/O phase, processes perform I/O for the merged request. If the merged request is not contiguous by itself, data sieving is used to obtain contiguous accesses. In the communication phase, processes redistribute data among themselves to achieve the desired distribution. For reading, the first phase is the I/O phase, and the second phase is the communication phase. For writing, it is the reverse. The additional cost of the communication phase is negligible compared with the benefit obtained by performing I/O contiguously. As in data sieving, ROMIO uses a constant amount of additional memory for performing collective I/O, which can be controlled by the user at run time. The default buffer size is 4 Mbytes for both reading and writing, as locks are not needed in the case of collective writes. The user can also control the number of processes that perform I/O in the I/O phase, which is useful on systems where the I/O performance does not scale with the number of processes making concurrent requests. By default, all processes perform I/O.
To enable the maximum amount of merging and larger accesses, the user's collective request must be a level-3 request rather than a level-1 request.
When the user specifies complete access information in a single I/O function call, the MPI-IO implementation or file system does not need to guess what the future accesses will be. ROMIO does not perform caching or prefetching on its own, but most file systems (on top of which ROMIO is implemented) do. By performing data sieving and collective I/O and making large requests to the file system, ROMIO enables the file system to perform better prefetching and caching than the file system could if it received thousands of small I/O requests.
We used two applications to measure the effect of using derived datatypes on performance: the distributed array example of Figure 2 and an unstructured code we obtained from Larry Schoof and Wilbur Johnson of Sandia National Laboratories. The unstructured code is a synthetic benchmark designed to emulate the I/O access pattern in unstructured-grid applications. It generates a random irregular mapping from the local one-dimensional array of a process to a global array in a common file shared by all processes. The mapping specifies where each element of the local array is located in the global array. The size of each element can also be varied in the program.
We modified the I/O portions of these applications to correspond to each of the four levels of requests and ran the programs on five different parallel machines using ROMIO as the MPI-IO implementation. The five machines were the HP Exemplar and SGI Origin2000 at the National Center for Supercomputing Applications (NCSA), the IBM SP at Argonne National Laboratory, the Intel Paragon at California Institute of Technology, and the NEC SX-4 at the National Aerospace Laboratory (NLR) in Holland. We used the native file systems on each machine: HFS on the Exemplar, XFS on the Origin2000, PIOFS on the SP, PFS on the Paragon, and SFS on the SX-4. These file systems were configured as follows at the time we performed the experiments: HFS on the Exemplar was configured on twelve disks. XFS on the Origin2000 had two RAID units with SCSI-2 interfaces. The SP had four servers for PIOFS, and each server had four SSA disks attached to it in one SSA loop. We used PIOFS's default striping unit of 64 Kbytes. (Note that ROMIO does not use the logical-views feature of PIOFS; that is, the file is considered as a linear sequence of bytes.) The Paragon had 64 I/O nodes for PFS, each with an individual Seagate disk. We used PFS's default striping unit of 64 Kbytes. SFS on the NEC SX-4 was configured on a single RAID unit comprising sixteen SCSI-2 data disks.
Tables 1 and 2 show the read
performance for the distributed-array example and the unstructured
code. The write performance is shown in Tables 3
and 4. The performance was measured without
explicitly calling an MPI_File_sync to flush all cached data
to disk. Some of the performance results may therefore include caching
performed by the file system. We did not include MPI_File_sync
in the measurements, because users most often do not perform a file
sync; they just open, read/write, and close. In all experiments, we
used the default values of the buffer sizes for data sieving and
collective I/O in ROMIO (see Sections 5.1 and 5.2). For the unstructured code, we used
a smaller grid size on the Origin2000 because of memory limitations.
| Bandwidth (Mbytes/s) | ||||
|---|---|---|---|---|
| Machine | Processors | Level 0/1 | Level 2 | Level 3 |
| HP Exemplar | 64 | 5.42 | 14.2 | 68.2 |
| IBM SP | 64 | 2.13 | 11.9 | 90.2 |
| Intel Paragon | 256 | 3.01 | 9.50 | 132 |
| NEC SX-4 | 8 | 0.71 | 322 | 563 |
| SGI Origin2000 | 32 | 14.0 | 118 | 175 |
| Bandwidth (Mbytes/s) | ||||
|---|---|---|---|---|
| Machine | Processors | Grid Points | Level 2 | Level 3 |
| HP Exemplar | 64 | 8 million | 3.15 | 35.0 |
| IBM SP | 64 | 8 million | 1.63 | 73.3 |
| Intel Paragon | 256 | 8 million | 1.18 | 78.4 |
| NEC SX-4 | 8 | 8 million | 152 | 101 |
| SGI Origin2000 | 32 | 4 million | 30.0 | 80.8 |
| Bandwidth (Mbytes/s) | ||||
|---|---|---|---|---|
| Machine | Processors | Level 0/1 | Level 2 | Level 3 |
| HP Exemplar | 64 | 0.54 | 1.25 | 50.7 |
| IBM SP | 64 | 1.85 | 1.85 | 57.6 |
| Intel Paragon | 256 | 1.12 | 3.33 | 183 |
| NEC SX-4 | 8 | 0.62 | 75.3 | 447 |
| SGI Origin2000 | 32 | 5.06 | 13.1 | 66.7 |
| Bandwidth (Mbytes/s) | ||||
|---|---|---|---|---|
| Machine | Processors | Grid Points | Level 2 | Level 3 |
| HP Exemplar | 64 | 8 million | 0.18 | 22.1 |
| IBM SP | 64 | 8 million | xx | 37.8 |
| Intel Paragon | 256 | 8 million | 0.22 | 94.9 |
| NEC SX-4 | 8 | 8 million | 16.8 | 81.5 |
| SGI Origin2000 | 32 | 4 million | 1.33 | 59.2 |
If the requests of processes that call a collective-I/O function are not interleaved in the file, ROMIO's collective-I/O implementation just calls the corresponding independent-I/O function on each process. For the distributed-array example, therefore, level-1 requests perform the same as level-0 requests. If the accesses in a level-1 request are interleaved or overlapping (e.g., in a read-broadcast type of access pattern), ROMIO implements the level-1 request collectively, and the performance is better than with a level-0 request.
For level-2 requests, ROMIO performs data sieving. Depending on the machine, we observed an improvement in read performance ranging from 162% (HP Exemplar) to 45,252% (NEC SX-4) for the distributed-array example. The improvement in write performance varied from 0% (IBM SP) to 12,045% (NEC SX-4). ROMIO cannot perform data sieving on level-2 write requests on the SP's PIOFS file system, because PIOFS does not support file locking. ROMIO therefore translates level-2 write requests on PIOFS into level-0 requests. As a result, no performance improvement was observed with level-2 write requests on PIOFS.
In the unstructured code, the I/O access pattern is irregular, and the granularity of each access is very small (64 bytes). Level-0 requests are not feasible for this kind of application, as they take an inordinate amount of time. We therefore do not present level-0/1 results for the unstructured code. Since level-2 writes on PIOFS get translated to level-0 writes, we also do not present results for level-2 writes on PIOFS.
ROMIO performs collective I/O in the case of level-3 requests. Within the collective-I/O implementation, ROMIO also performs data sieving when there are holes in the merged request. In these two applications, however, the merged request had no holes. Collective I/O improved the performance of level-3 requests significantly. For the distributed-array example, the improvement in read performance was as high as 79,196% over level-0/1 requests (NEC SX-4) and as high as 1,289% over level-2 requests (Intel Paragon). For the unstructured code, the improvement in read performance was as high as 6,544% over level-2 requests (Intel Paragon). The write performance showed similar improvements. An unusual result was observed on the NEC SX-4 for the unstructured code: The read performance of level-2 requests was higher than that of level-3 requests. We attribute this result to the high read bandwidth of NEC's Supercomputing File System (SFS), because of which data sieving by itself outperformed the extra communication required for collective I/O.
MPI-IO has the potential to help users achieve better I/O performance in parallel applications. On their part, users must use some of the special features of MPI-IO. In particular, when accesses are noncontiguous, users must strive to create derived datatypes and define file views. Our results show that performance can improve by orders of magnitude when users create derived datatypes and use the collective-I/O functions.
We believe that such performance improvements can also be expected in applications other than those considered in this paper. In particular, we plan to extend this study to applications such as out-of-core FFT, external sorting, and database applications.
We note that the MPI-IO standard does not require an implementation to perform any of these optimizations. Nevertheless, even if an implementation does not perform any optimization and instead translates level-3 requests into several level-0 requests to the file system, the performance would be no worse than if the user made level-0 requests by hand.
readv and
writev, but they allow noncontiguity only in memory and not in
the file. POSIX has a function lio_listio that allows the user
to specify a list of requests at a time, but implementations of
lio_listio internally treat each request in the list separately;
that is, they do not merge the requests into larger requests or perform
data sieving (see Section 5.1). Furthermore, since the
lio_listio interface is not collective, implementations cannot
perform collective I/O.2In this figure, levels 1 and 2 represent the same amount of data per request, but, in general, when the number of noncontiguous accesses per process is greater than the number of processes, level 2 represents more data than level 1.
3An MPI communicator is used in the open call to specify the participating processes, and the communicator could represent any subset (or all) of the processes of the application.
We thank Larry Schoof and Wilbur Johnson for providing the unstructured code used in this paper.
This work was supported by the Mathematical, Information, and Computational Sciences Division subprogram of the Office of Computational and Technology Research, U.S. Department of Energy, under Contract W-31-109-Eng-38; and by the Scalable I/O Initiative, a multiagency project funded by the Defense Advanced Research Projects Agency (contract number DABT63-94-C-0049), the Department of Energy, the National Aeronautics and Space Administration, and the National Science Foundation.
http://www.mpi-forum.org/docs/docs.html.
http://www.mpi-forum.org/docs/docs.html.
Rajeev Thakur is an assistant computer scientist in the
Mathematics and Computer Science Division at Argonne National
Laboratory. He received a Ph.D. in computer engineering from Syracuse
University in 1995. His research interests are in parallel I/O
and large-scale scientific data management. He participated in the
MPI-2 Forum to define a standard, portable interface for parallel I/O
(MPI-IO). He is currently developing a high-performance, portable
MPI-IO implementation, called ROMIO.
William Gropp is a senior computer scientist in the Mathematics
and Computer Science Division at Argonne National Laboratory. After
receiving his Ph.D. in computer science from Stanford University in
1982, he held the positions of assistant (1982-1988) and associate
(1988-1990) professor in the Computer Science Department at Yale
University. In 1990, he joined the numerical-analysis group at
Argonne. His research interests are in parallel computing, software
for scientific computing, and numerical methods for partial
differential equations. He is a co-author of Using MPI: Portable
Parallel Programming with the Message-Passing Interface and is a
chapter author in the MPI-2 Forum. His current projects include the
design and implementation of MPICH, a portable MPI implementation; the
design and implementation of PETSc,
a parallel, numerical library for PDEs; and research into programming
models for parallel architectures.
Ewing (Rusty) Lusk is a senior computer scientist in the Mathematics
and Computer Science Division at Argonne National Laboratory. After
receiving his Ph.D. in mathematics from the University of Maryland in
1970, he taught first in the Mathematics Department and later in the
Computer Science Department at Northern Illinois University before
joining Argonne National Laboratory in 1982. He has been involved in
the MPI standardization effort both as an organizer of the MPI-2 Forum
and as a designer and implementor of the MPICH portable implementation
of MPI. His current projects include design and
implementation of the MPI-2 extensions to MPICH and research into
programming models for parallel architectures. Past interests include
automated theorem-proving, logic programming, and parallel
computing. He is a co-author of several books in automated reasoning
and parallel computing, including Using MPI: Portable Parallel
Programming with the Message-Passing Interface.