UMap
Workloads in HPC and cloud alike require interaction with large datastores
in flat files or structured databases for a wide spectrum of
analytics. Programmer productivity is greatly enhanced by mapping
datastores into an application process’ virtual memory space to provide a
unified “in-memory” interface. Currently, memory mapping is provided by the
mmap system service that is optimized for generality and
reliability. However, scalability at high concurrency is a formidable
challenge on many-core systems. Also, there is a need for extensibility to
support application-specific access patterns and new, potentially
disaggregated datastores.
The User Level Memory Map (UMap) is a memory map approach to incorporating datastores residing in a complex memory/storage hierarchy into an application process address space. UMap is a scalable and extensible user-space service for memory-mapping datastores. The datastore can reside in local SSD, global storage, or can be distributed in a disaggregated memory. By exploiting large virtual address spaces, datastores can be accessed directly as if in memory; this is particularly well suited to analyzing large observational and simulation data. Through decoupled queue management, concurrency aware adaptation, and dynamic load balancing, UMap enables application performance to scale even at high concurrency.
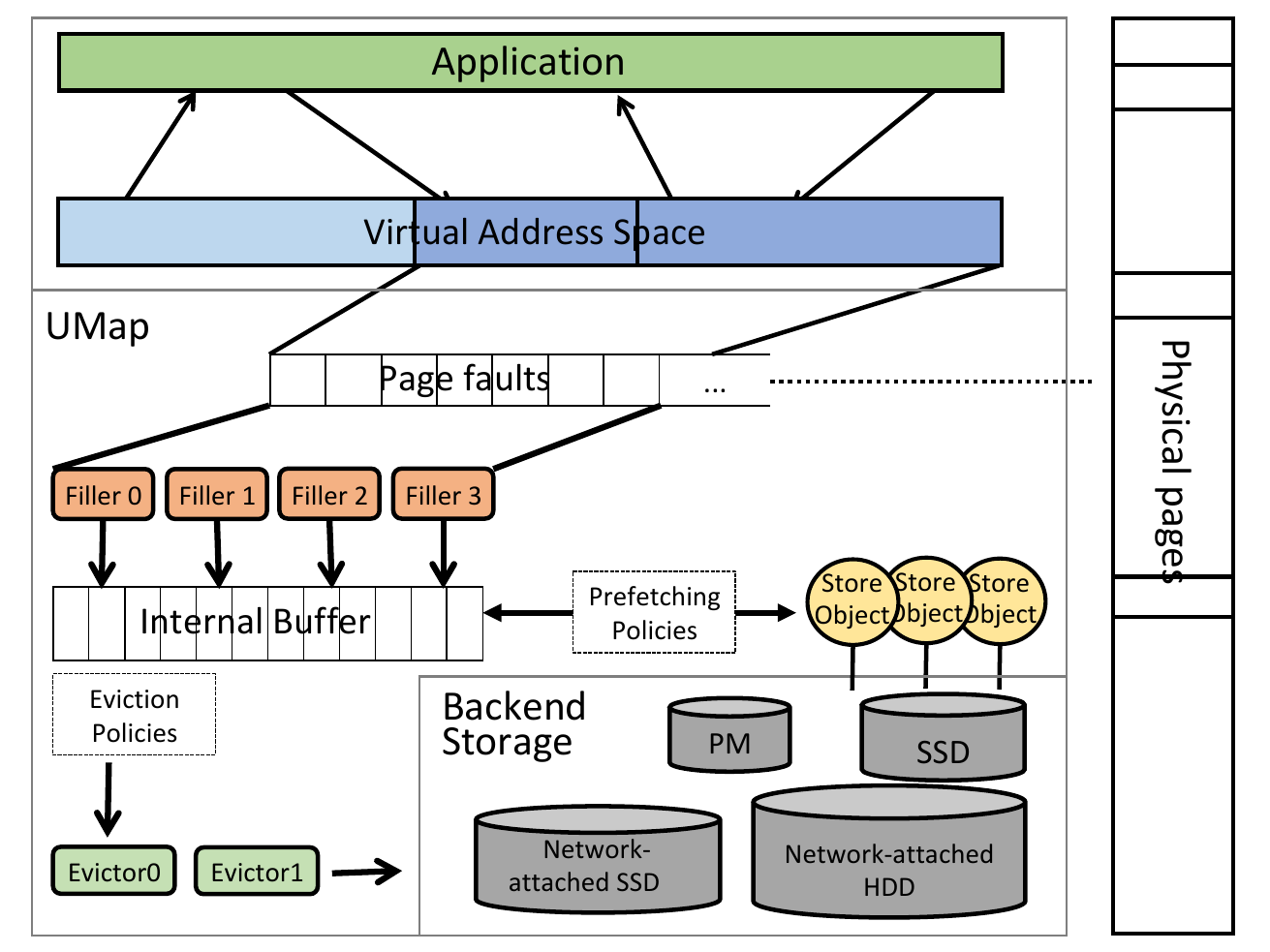 As a user-space library, UMap is flexible, easy to use, and runs on
commodity Linux kernels >=5.10. The first figure outlines UMap
architecture. The UMap handler manages migration of pages between far
(e.g., Backend Storage) and local memory. It uses the low-overhead
As a user-space library, UMap is flexible, easy to use, and runs on
commodity Linux kernels >=5.10. The first figure outlines UMap
architecture. The UMap handler manages migration of pages between far
(e.g., Backend Storage) and local memory. It uses the low-overhead
userfaultfd protocol, enabling applications to handle page faults in user
space. The UMap handler receives a page fault notification as a message and
loads the requested page from a user-defined datastore that could reside in
Persistent Memory (PM), SSD, network-attached memory, etc. UMap supports
highly customizable paging management since it runs in the application
context. A UMap handler can perform application-specific prefetching and
caching policies, support multiple page sizes (multiple of system page),
configure the page buffer size to application needs, and provide
application-specified number of workers to fill and evict pages.
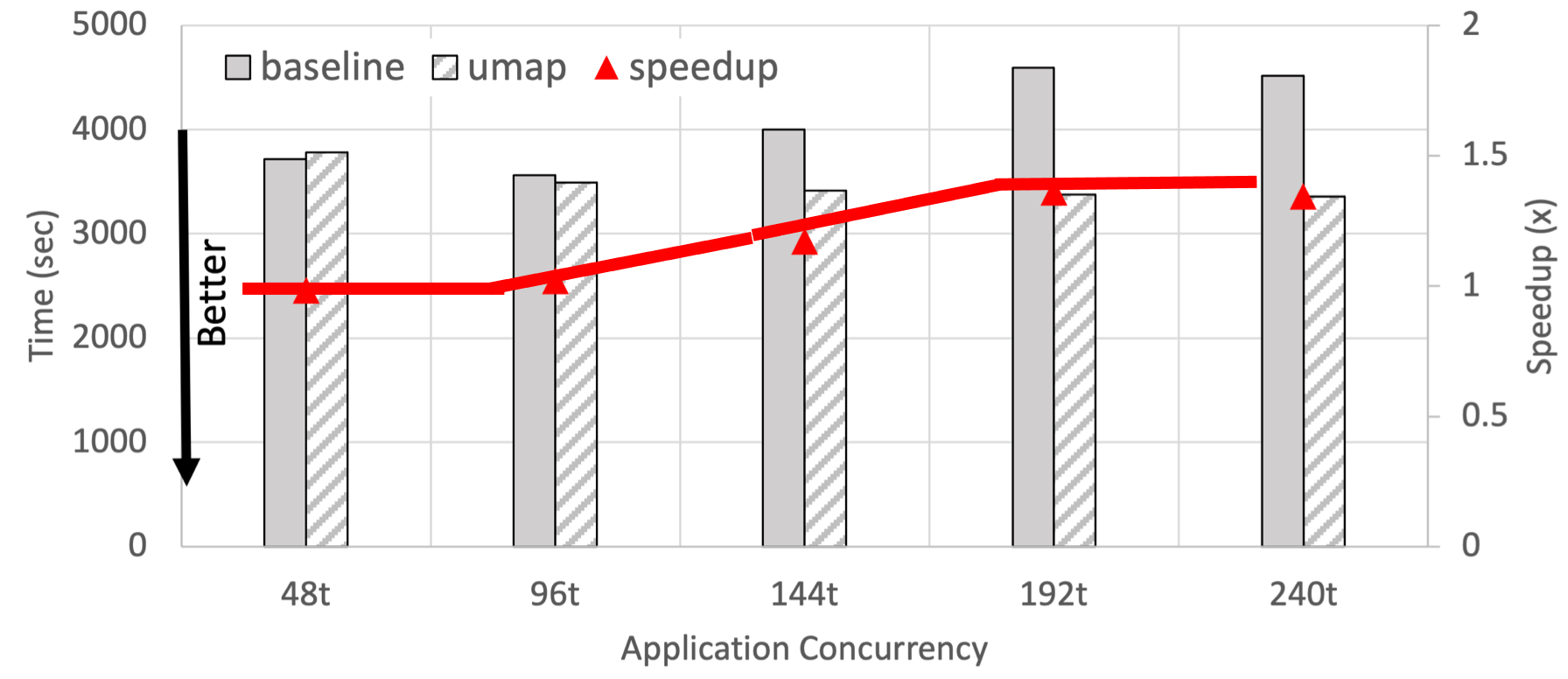 The second figure illustrates that UMap enables performance improvement
over the kernel solution in a production application, the Livermore
Metagenomics Toolkit (LMAT), at increased application concurrency. The
application memory maps a large custom K-mer database that typically
exceeds the DRAM capacity on a single machine (1.5 TB in this
example). It then performs classification by searching the databases for
batches of k-mer queries concurrently.
The second figure illustrates that UMap enables performance improvement
over the kernel solution in a production application, the Livermore
Metagenomics Toolkit (LMAT), at increased application concurrency. The
application memory maps a large custom K-mer database that typically
exceeds the DRAM capacity on a single machine (1.5 TB in this
example). It then performs classification by searching the databases for
batches of k-mer queries concurrently.
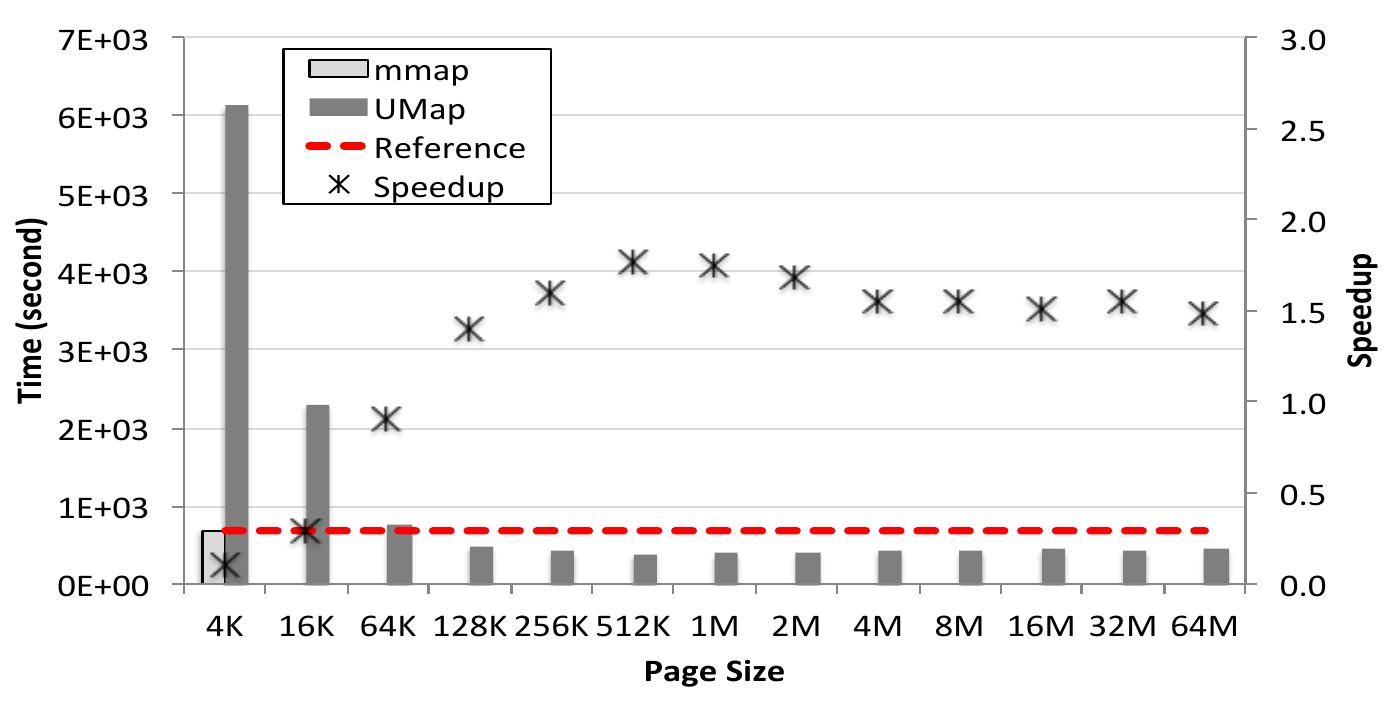 Another class of applications we studied is out-of-core graph algorithms
that generate an edge or adjacency list representation of graphs from raw
data (e.g., Wikimedia Commons edits) and traverse the graphs to compute
features of interest for community detection. The third figure shows that
supporting variable page sizes in UMap can achieve more than 1.5 times
speedup over the kernel solution for BFS on a 500 GB graph.
Another class of applications we studied is out-of-core graph algorithms
that generate an edge or adjacency list representation of graphs from raw
data (e.g., Wikimedia Commons edits) and traverse the graphs to compute
features of interest for community detection. The third figure shows that
supporting variable page sizes in UMap can achieve more than 1.5 times
speedup over the kernel solution for BFS on a 500 GB graph.
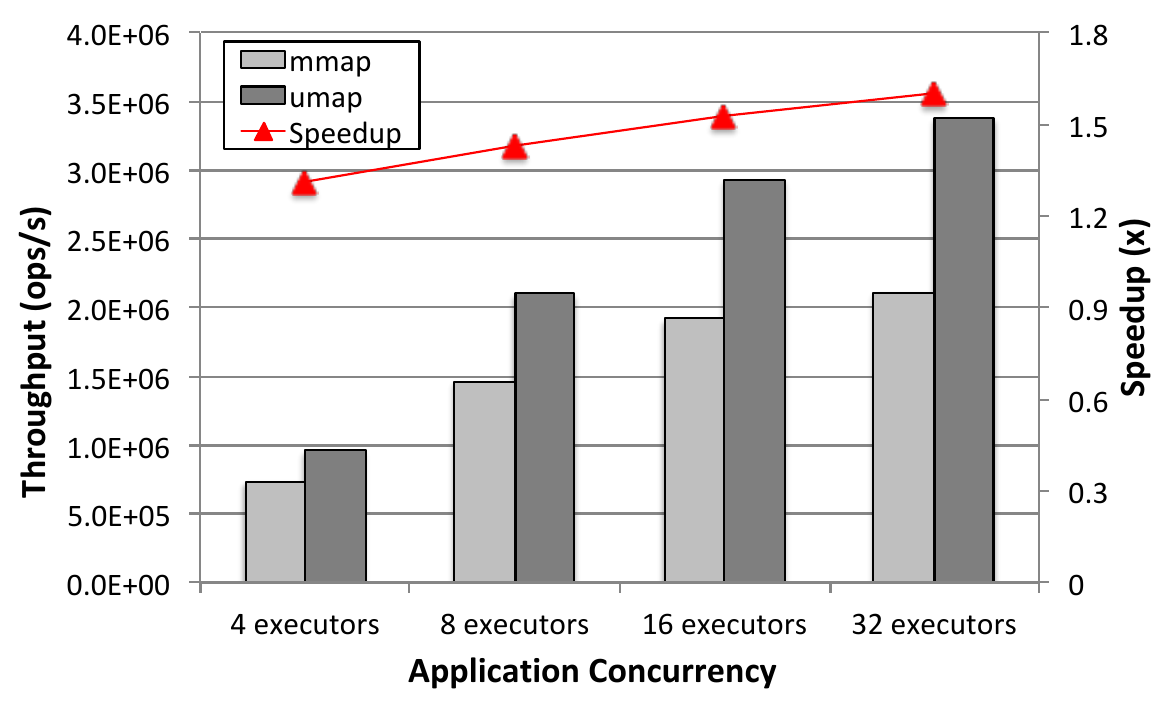 We also studied the use case of in-memory databases that use slower PM or
SSD to expand their memory capacity. The fourth figure shows the
scalability achieved by tuning the number of workers in UMap to support
YCSB workloads on the N-Store database.
We also studied the use case of in-memory databases that use slower PM or
SSD to expand their memory capacity. The fourth figure shows the
scalability achieved by tuning the number of workers in UMap to support
YCSB workloads on the N-Store database.
More information on UMap can be found in its documentation on Read the Docs. For a complete list of UMap-related resources, check the For Developers page.
Maya Gokhale, Ivy Peng, Abhik Sarkar, Eric Green, Roger Pearce, Keita Iwabuchi (LLNL)