NRM
Argo Node Resource Manager (NRM) is a daemon running on the compute nodes. It centralizes node management activities such as:
- job management,
- resource management, and
- power management.
Resource Management
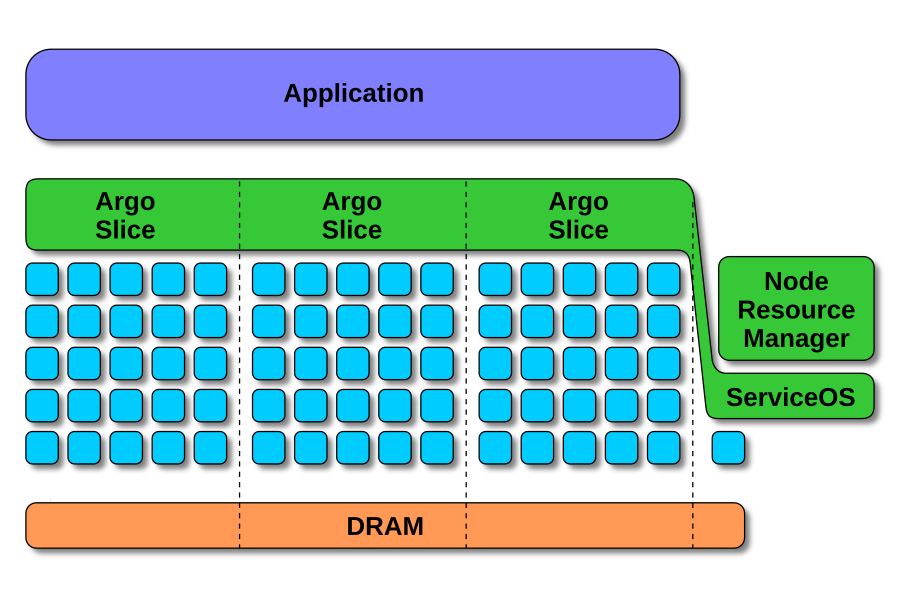 Argo uses slices for resource management. Physical resources on the
compute nodes are divided into separate partitions. Slices can be used to
separate individual components of parallel workloads, in addition to
cordoning off system services; this physical separation ensures an improved
performance isolation between components. The first figure shows Argo
slices dividing node CPU (blue squares) and memory (orange bar) resources
between three application components, with an additional partition left
aside for system services.
Argo uses slices for resource management. Physical resources on the
compute nodes are divided into separate partitions. Slices can be used to
separate individual components of parallel workloads, in addition to
cordoning off system services; this physical separation ensures an improved
performance isolation between components. The first figure shows Argo
slices dividing node CPU (blue squares) and memory (orange bar) resources
between three application components, with an additional partition left
aside for system services.
Our slices can currently manage the following:
- CPU cores (hardware threads)
- Memory (including physical memory at sub-NUMA granularity with a patched Linux kernel)
- Kernel task scheduling class
The physical resources are partitioned primarily by using the
cgroupsmechanism of the Linux kernel. Work is under way to extend the management to I/O bandwidth as well as to the partitioning of last-level CPU cache using Intel’s Cache Allocation Technology.
The NRM daemon maps slices to the node’s hardware topology, arbitrating resources between applications and runtime services. Resources can be dynamically reconfigured at run time; interfaces are provided for use from applications and from global services.
Argo slices are meant to be transparent to applications; in particular, they have been tested to work with MPI codes. They do not impede communication between application components, since they do not utilize namespaces; they are also compatible with (and complementary to) container runtimes such as Docker, Singularity, or Shifter.
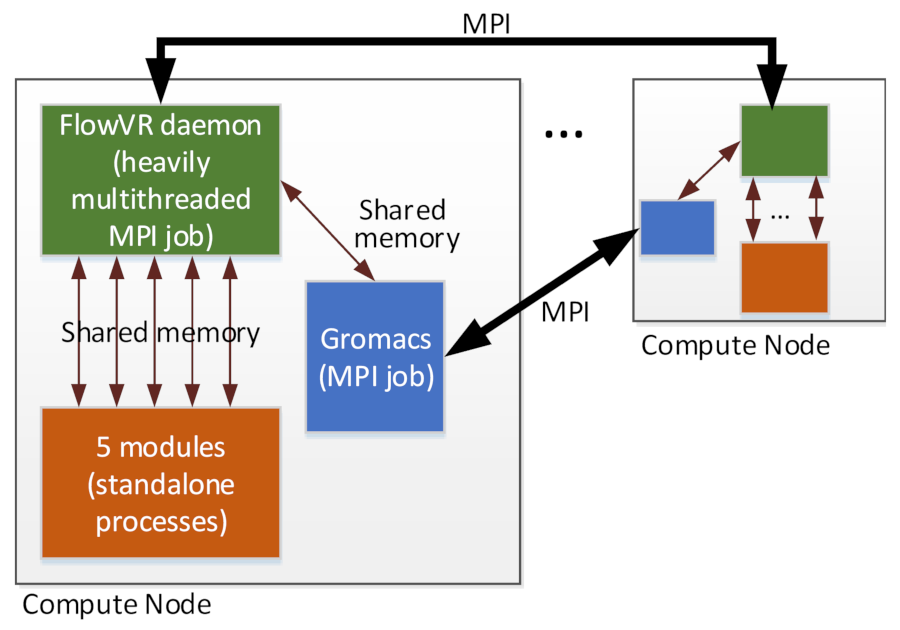 Partitioning node resources can be particularly important for complex
workloads consisting of multiple heterogeneous components, for example,
coupled codes, simulations running in parallel with in situ analytics, and
workflows. If a compute node is shared among multiple workload components
(a likely scenario considering the reduced cost of data transfers), these
components—if allowed to freely share node resources—could interfere
with one another, resulting in suboptimal performance. The figure depicts
a complex application workflow we used during an early development of Argo
slices.
Partitioning node resources can be particularly important for complex
workloads consisting of multiple heterogeneous components, for example,
coupled codes, simulations running in parallel with in situ analytics, and
workflows. If a compute node is shared among multiple workload components
(a likely scenario considering the reduced cost of data transfers), these
components—if allowed to freely share node resources—could interfere
with one another, resulting in suboptimal performance. The figure depicts
a complex application workflow we used during an early development of Argo
slices.
Power Management
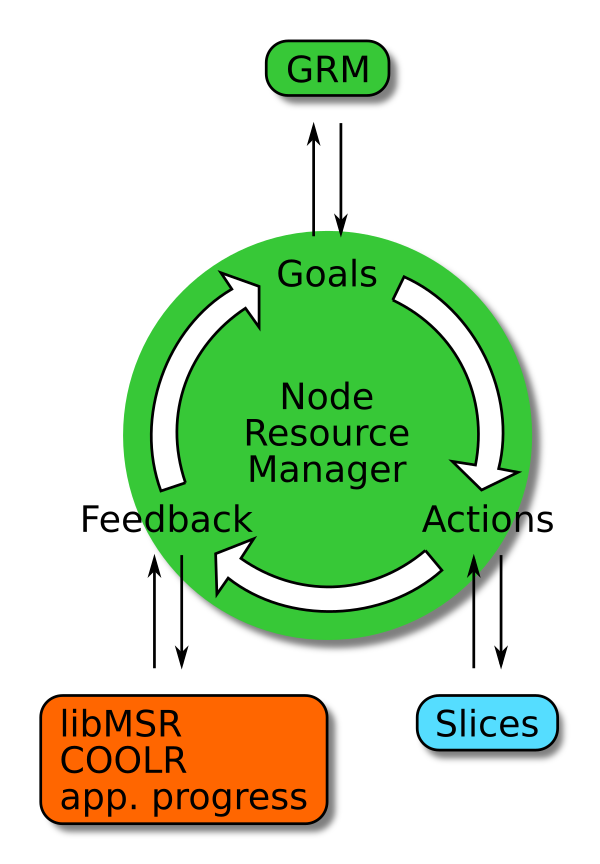 The NRM daemon also manages power at the node level. As depicted in the
figure, it works in a closed control loop, obtaining goals (power limit)
from the GRM, acting on application workloads launched within slices by,
for example, adjusting the CPU p-states or changing the power cap via the
Intel RAPL mechanism, and getting feedback through the monitoring of
hardware sensors measuring, for example, power draw, temperature, fan
speed, and frequency.
The NRM daemon also manages power at the node level. As depicted in the
figure, it works in a closed control loop, obtaining goals (power limit)
from the GRM, acting on application workloads launched within slices by,
for example, adjusting the CPU p-states or changing the power cap via the
Intel RAPL mechanism, and getting feedback through the monitoring of
hardware sensors measuring, for example, power draw, temperature, fan
speed, and frequency.
Critical to the success of this approach is the self-reporting by applications. We provide a simple API that application processes can use to periodically update the NRM on their progress. This gives NRM reliable feedback on the efficacy of its power policies, and it can also be used for a more robust identification of the critical path, rather than relying on heuristics based on performance counters.
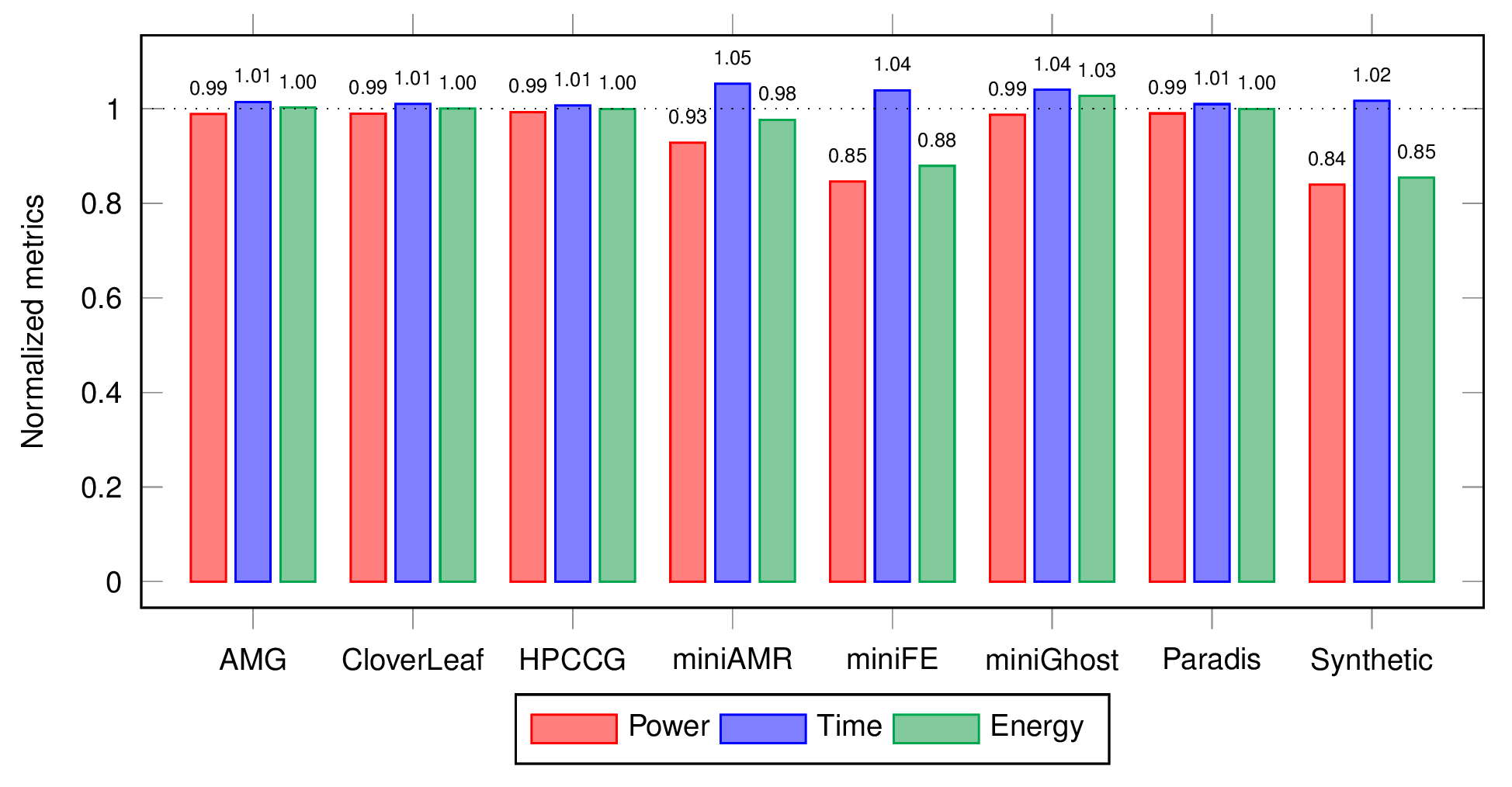 The final figure shows the results from early experiments with a
bulk-synchronous parallel application-aware power policy on a number of
benchmarks and applications. NRM identifies the critical path across
application phases to dynamically adapt power, showing an energy reduction
of up to 15%.
The final figure shows the results from early experiments with a
bulk-synchronous parallel application-aware power policy on a number of
benchmarks and applications. NRM identifies the critical path across
application phases to dynamically adapt power, showing an energy reduction
of up to 15%.
More information on NRM can be found in its documentation on Read the Docs. For a complete list of NRM-related resources, check the For Developers page.
Swann Perarnau, John-Luke Navarro, Kazutomo Yoshii, Kamil Iskra, Pete Beckman (ANL)