AML
AML provides explicit, application-aware memory management for deep memory systems. It offers a collection of building blocks that are generic, customizable, and composable. Applications can specialize the implementation of each offered abstraction and can mix and match the components as needed. AML can be used to create, for example, a software-managed scratchpad for multilevel DRAM hierarchy such as HBM and DDR. Such a scratchpad provides applications with a memory region with a predictable high performance for critical data structures.
We provide applications and runtimes with a descriptive API for data access, where all data placement decisions are explicit, and so is the movement of data between different memory types. At the same time, the API does abstract the memory topology and other device complexities. We focus on optimizing data locality for current and future hardware generations; applications provide insights for static allocations, and we can also dynamically and asynchronously remap to optimize for a particular data layout or to best take advantage of the memory hierarchy.
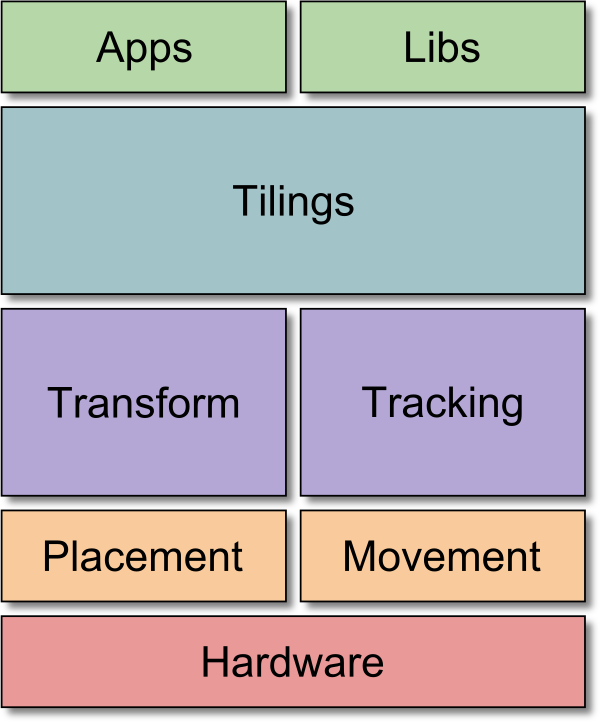 The first figure depicts the major components of AML, which include the
following:
The first figure depicts the major components of AML, which include the
following:
- Topology & hardware management (dependent on NUMA, hwloc, and SICM)
- Data layout descriptions (application-specific)
- Tiling schemes (including ghost areas)
- Data movement facilities (currently primarily
memcpyormove_pages) - Pipelining helpers (scratchpad, asynchronous requests)
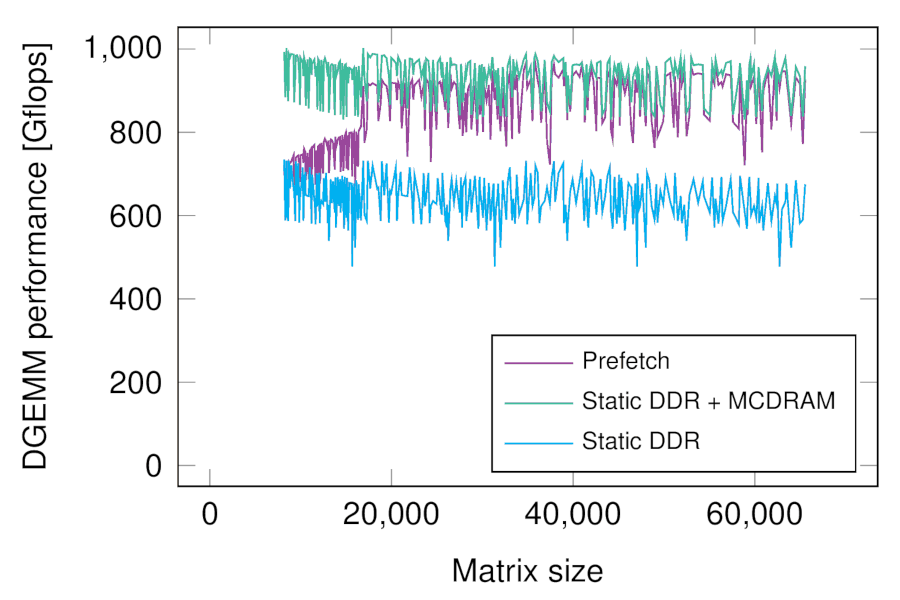 We conducted an experiment on an Intel Knights Landing system running in
flat/quad mode to verify the effectiveness of the AML prefetching using a
custom DGEMM implementation, which uses pipelining to move data between DDR
and MCDRAM, OpenMP tasks, and an inner kernel autotuned for AVX2. We
compared prefetching against two static allocation approaches: one where
all the data is in the regular DDR memory and one where it is optimally
distributed between DDR and MCDRAM. As shown in the second figure, the
prefetcher achieves performance equal to or better than that of the optimal
static allocation on inputs that exceed the capacity of MCDRAM.
We conducted an experiment on an Intel Knights Landing system running in
flat/quad mode to verify the effectiveness of the AML prefetching using a
custom DGEMM implementation, which uses pipelining to move data between DDR
and MCDRAM, OpenMP tasks, and an inner kernel autotuned for AVX2. We
compared prefetching against two static allocation approaches: one where
all the data is in the regular DDR memory and one where it is optimally
distributed between DDR and MCDRAM. As shown in the second figure, the
prefetcher achieves performance equal to or better than that of the optimal
static allocation on inputs that exceed the capacity of MCDRAM.
More information on AML can be found in its documentation on Read the Docs. For a complete list of AML-related resources, check the For Developers page.
Swann Perarnau, Brice Videau (ANL)